Abstract
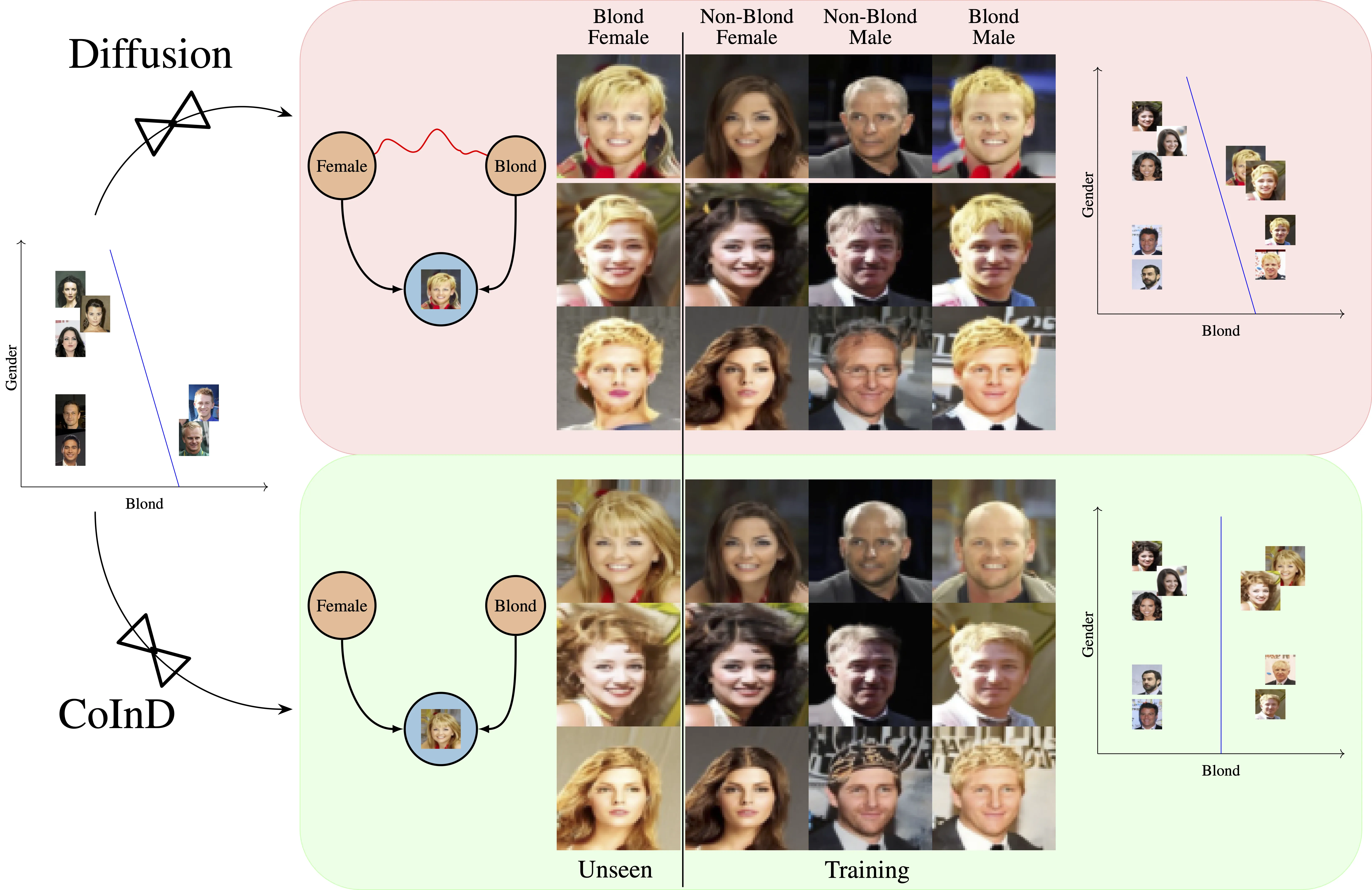
Machine learning systems struggle with robustness under subpopulation shifts. This problem becomes especially pronounced in scenarios where only a subset of attribute combinations is observed during training—a severe form of subpopulation shift, referred to as compositional shift. To address this problem, we ask: Can we improve the robustness by training on synthetic data, spanning all possible attribute combinations? We first show that training conditional diffusion models on limited data leads to incorrect underlying distribution. Therefore, synthetic data sampled from such models will result in unfaithful samples and will not lead to improved performance of downstream machine learning systems. To address this problem, we propose CoInD to reflect the compositional nature of the world by enforcing conditional independence through minimizing Fisher’s divergence between joint and marginal distributions. We demonstrate that synthetic data generated by CoInD is faithful, which translates to state-of-the-art worst-group accuracy on compositional shift tasks on CelebA.