Abstract
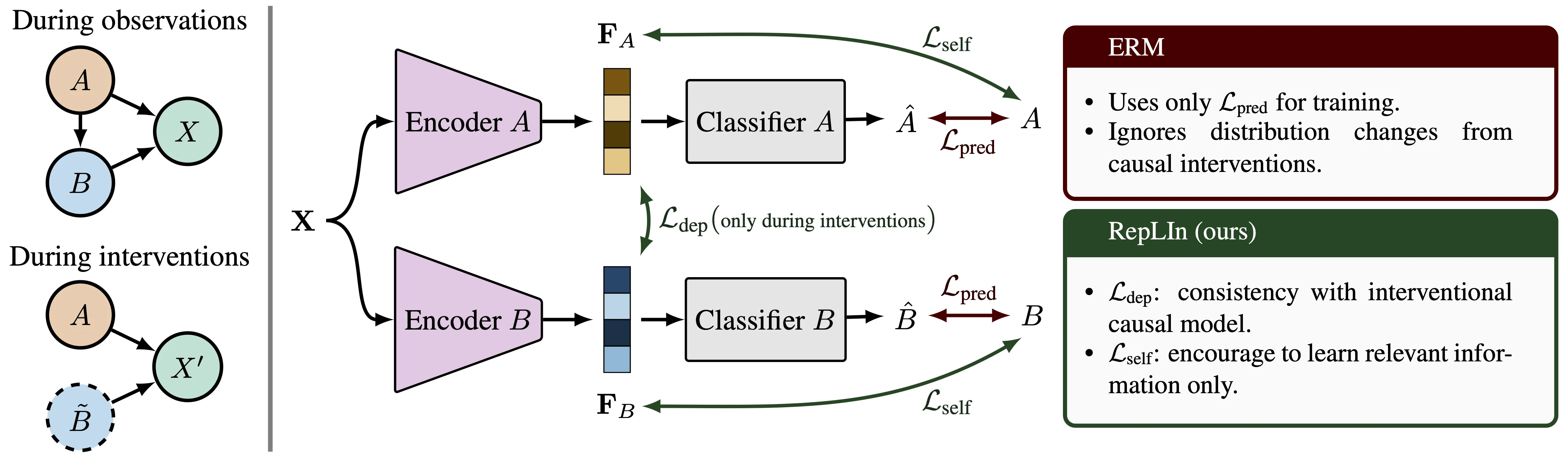
We study the problem of learning robust discriminative representations of causally related latent variables given the underlying causal graph and a training set comprising passively collected observational data and interventional data obtained through targeted interventions on some of these latent variables. We desire to learn representations that are robust against the resulting interventional distribution shifts. Existing approaches treat observational and interventional data alike, ignoring the independence relations arising from these interventions, even with known underlying causal models. As a result, their representations lead to large predictive performance disparities between observational and interventional data. This performance disparity worsens when interventional training data is scarce. In this paper, (1) we first identify a strong correlation between this performance disparity and the representations’ violation of statistical independence induced during interventions. (2) For linear models, we derive sufficient conditions on the proportion of interventional training data, for which enforcing statistical independence between representations of the intervened node and its non-descendants during interventions lowers the test-time error on interventional data. Combining these insights, (3) we propose RepLIn, a training algorithm that explicitly enforces this statistical independence between interventional representations. We demonstrate the utility of RepLIn on a synthetic dataset and on real image and text datasets on facial attribute classification and toxicity detection, respectively, with semi-synthetic causal structures. Our experiments show that RepLIn is scalable with the number of nodes in the causal graph and is suitable to improve robustness against interventional distribution shifts of both continuous and discrete latent variables compared to the ERM baselines.