Abstract
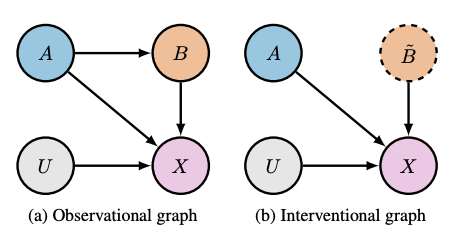
Spurious correlations occur when a model learns unreliable features from the data and are a well-known drawback of data-driven learning. Although there are several algorithms proposed to mitigate it, we have yet to jointly derive the indicators of spurious correlations. As a result, the solutions built upon standalone hypotheses fail to beat simple ERM baselines. We collect some of the commonly studied hypotheses behind the occurrence of spurious correlations and investigate their influence on standard ERM baselines using synthetic datasets generated from causal graphs. Subsequently, we observe patterns connecting these hypotheses and model design choices.