Supervised Learning Applications - II
CSE 891: Deep Learning
Wednesday November 04, 2020
Structured Output Prediction
- Traditional Learning: Mapping $f : \mathcal{X} \rightarrow \mathbb{R}$
- Structured Output Learning: Mapping $f : \mathcal{X} \rightarrow \mathcal{Y}$



Human Pose Estimation

Pose Estimation: Difficulty

Pose Estimation: Difficulty

Parts Model

Deformable Parts Model


Parts Model

Pose Estimation: Results
Dense Structured Output Prediction
- Recognizing and delineating objects in an image
- Classifying each pixel in the image
- A fully connected graphical model can account for contextual information in the image.

Dense CRF

- Pairwise energies are defined for every pixel pair in the image. \begin{equation} E(\mathbf{x}) = \sum_{i} unary(x_i) + \sum_{(i,j) \in G} pairwise(x_i,x_j) \nonumber \end{equation}
- Exact inference is not feasible.
- Use approximate mean field inference.
Mean Field Approximation

Unrolling Message Passing

Learning Message Passing

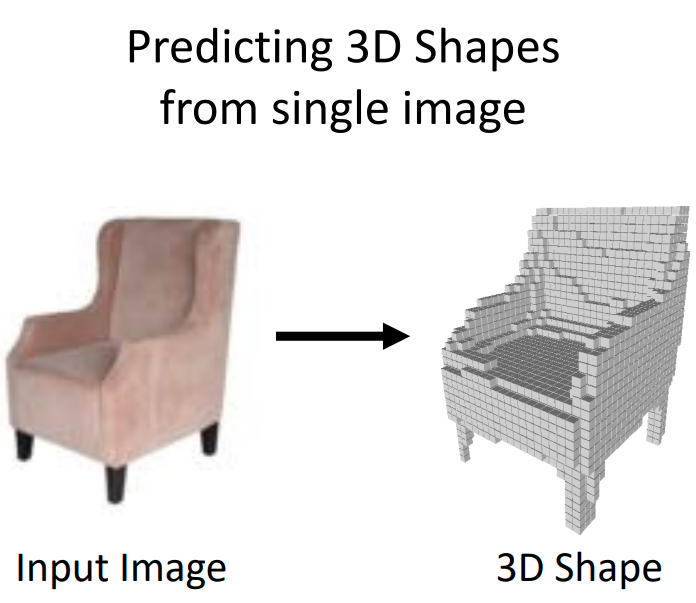
3D Computer Vision

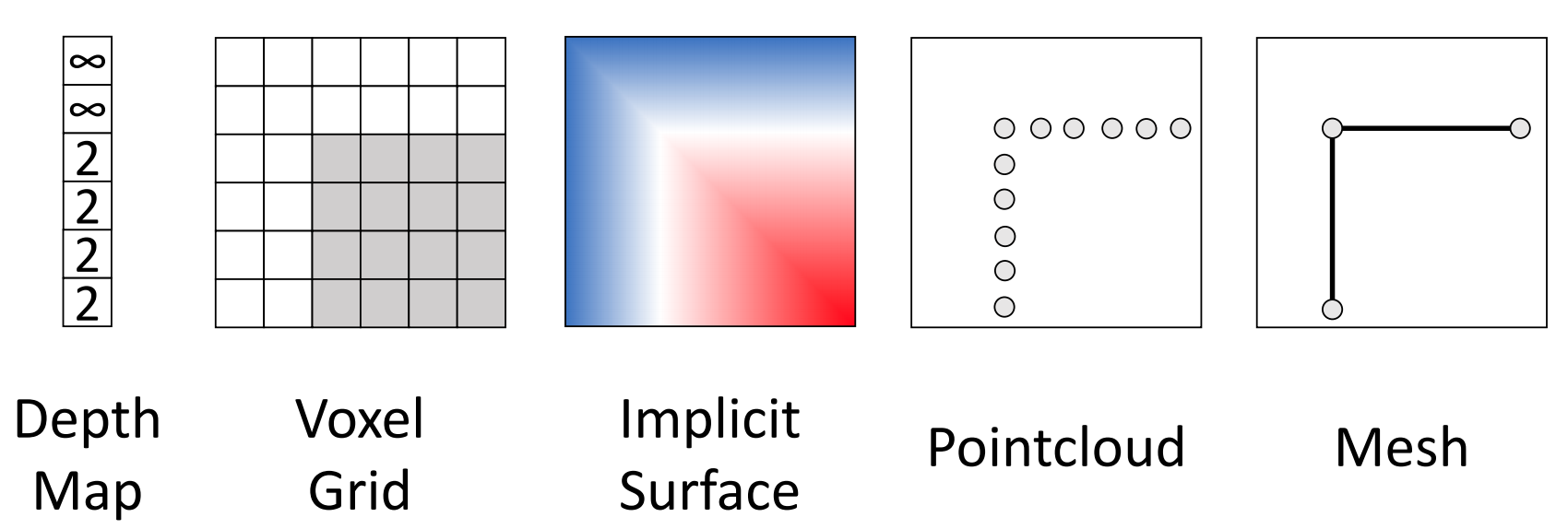
3D Representations
Depth Estimation

Depth Estimation Network
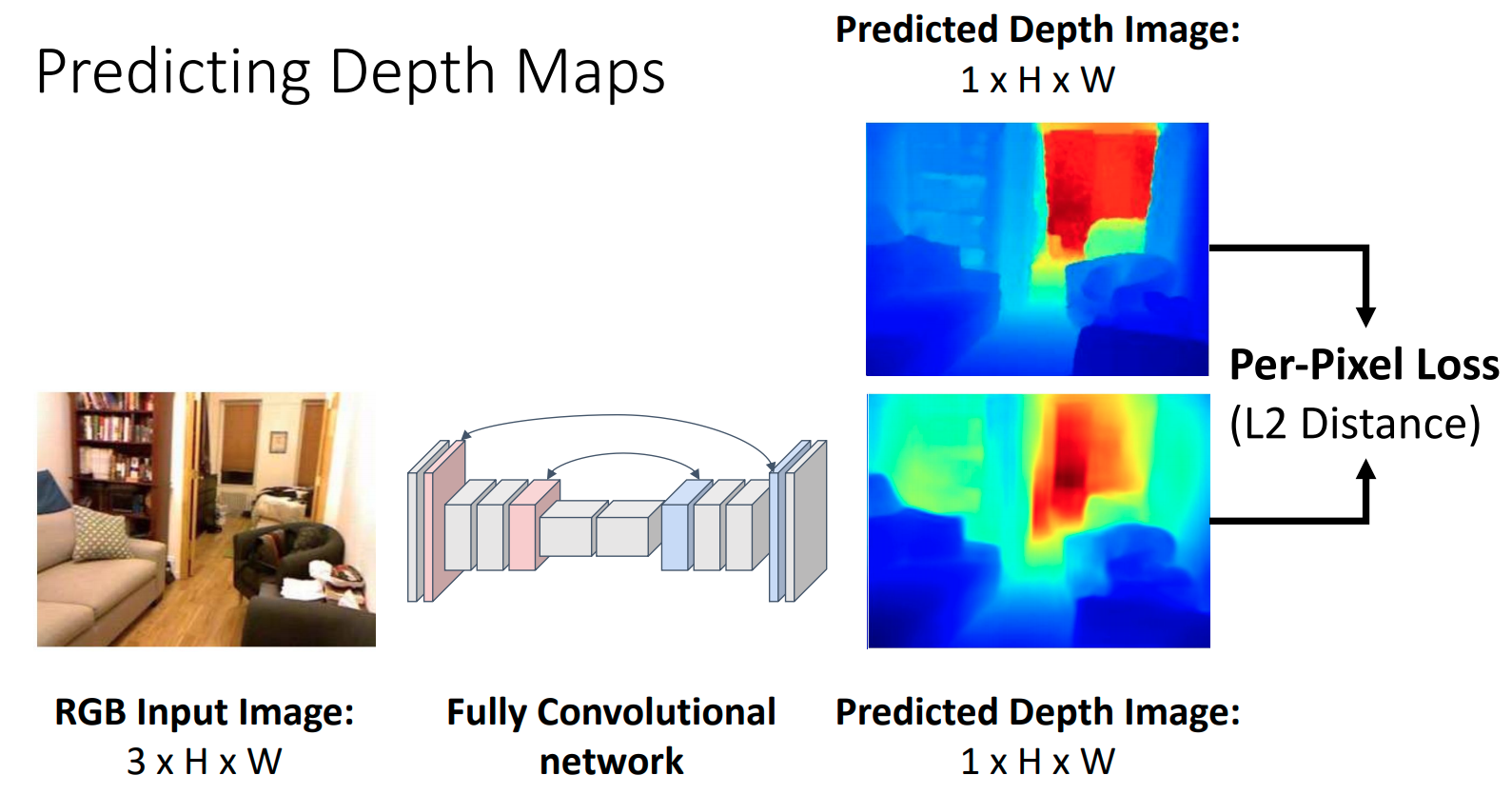
- Eigen, Puhrsh, and Fergus, “Depth Map Prediction from a Single Image using a Multi-Scale Deep Network”, NeurIPS 2014
- Eigen and Fergus, “Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture”, ICCV 2015
- Slide Credit: Justin Johnson
Depth Estimation Loss
- $L_2$ distance is scale variant
- Absolute scale/depth are ambiguous from a single image
- We need a scale invariant loss $$ \begin{equation} D(\mathbf{y},\mathbf{y}^*) = \frac{1}{2n^2}\sum_{i,j} \left( (\log y_i - \log y_j) - (\log y^*_i - \log y^*_j) \right)^2 \end{equation} $$
3D Surface Normal Estimation

3D Surface Normal Estimation Network

- Eigen and Fergus, “Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture”, ICCV 2015
- Slide Credit: Justin Johnson
Pixel2Mesh
- Key Ideas:
- Iterative Refinement
- Graph Convolution
- Vertex ALigned Features
- Chamfer Loss Function
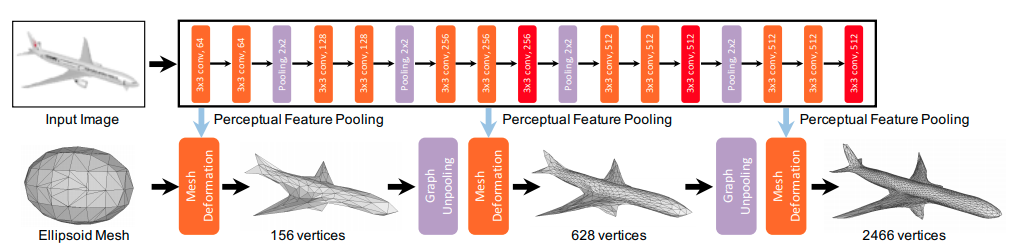
- Wang et al, "Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images", ECCV 2018
Motion Deblurring
- Purohit et al "Region-Adaptive Dense Network for Efficient Motion Deblurring" AAAI 2019
- Purohit et al "Spatially-Attentive Patch-Hierarchical Network for Adaptive Motion Deblurring" CVPR 2020

Motion Deblurring Results
- Purohit et al "Region-Adaptive Dense Network for Efficient Motion Deblurring" AAAI 2019
- Purohit et al "Spatially-Attentive Patch-Hierarchical Network for Adaptive Motion Deblurring" CVPR 2020


Video from Single Motion Blurred Image


- Purohit et al "Bringing Alive Blurred Moments" CVPR 2019
Video from Single Motion Blurred Image
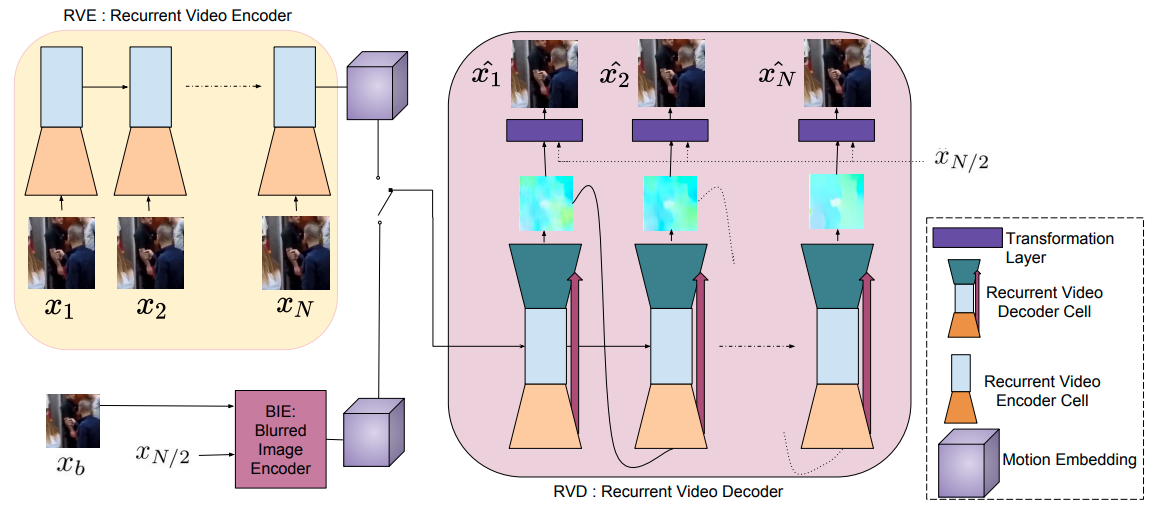
- Purohit et al "Bringing Alive Blurred Moments" CVPR 2019
Knowledge Distillation: Key Idea

- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Knowledge Distillation: Idea Map
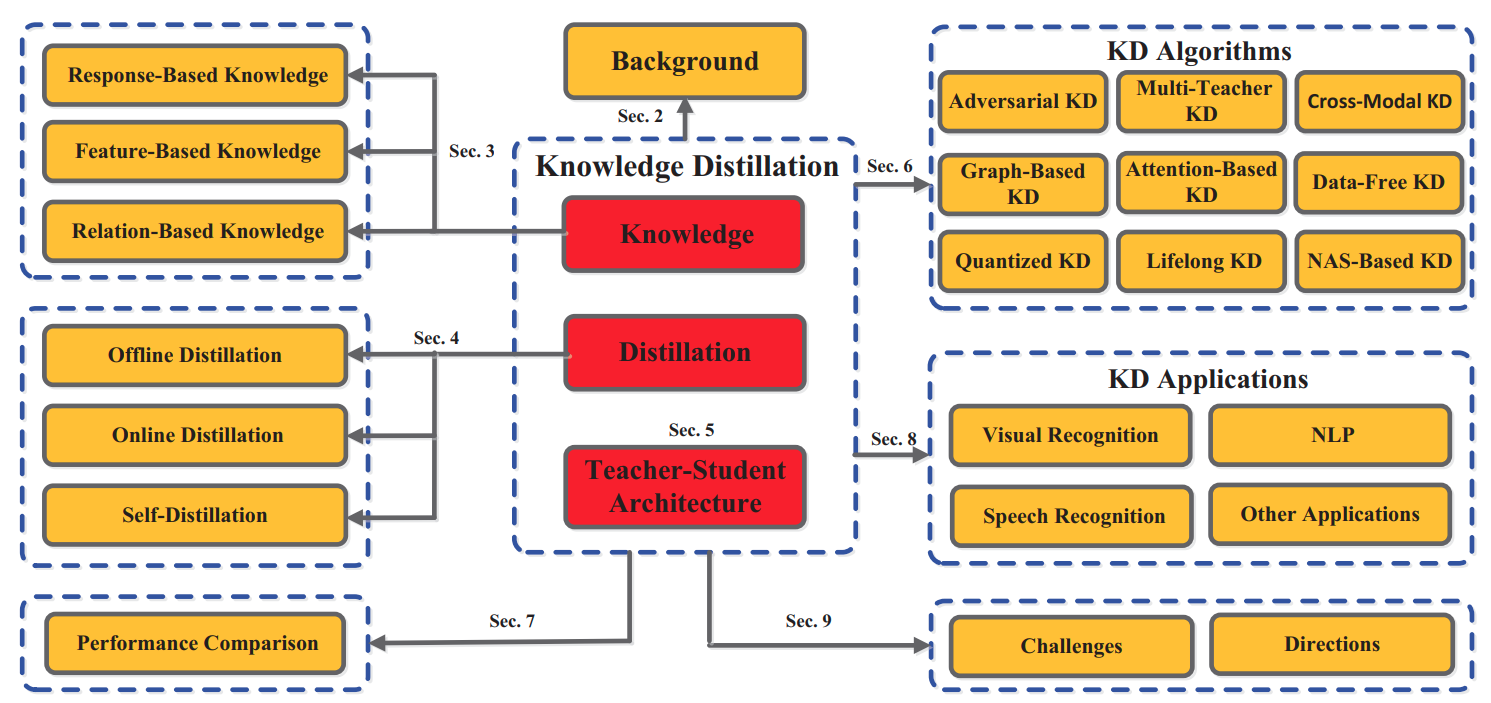
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
What Should We Distill?
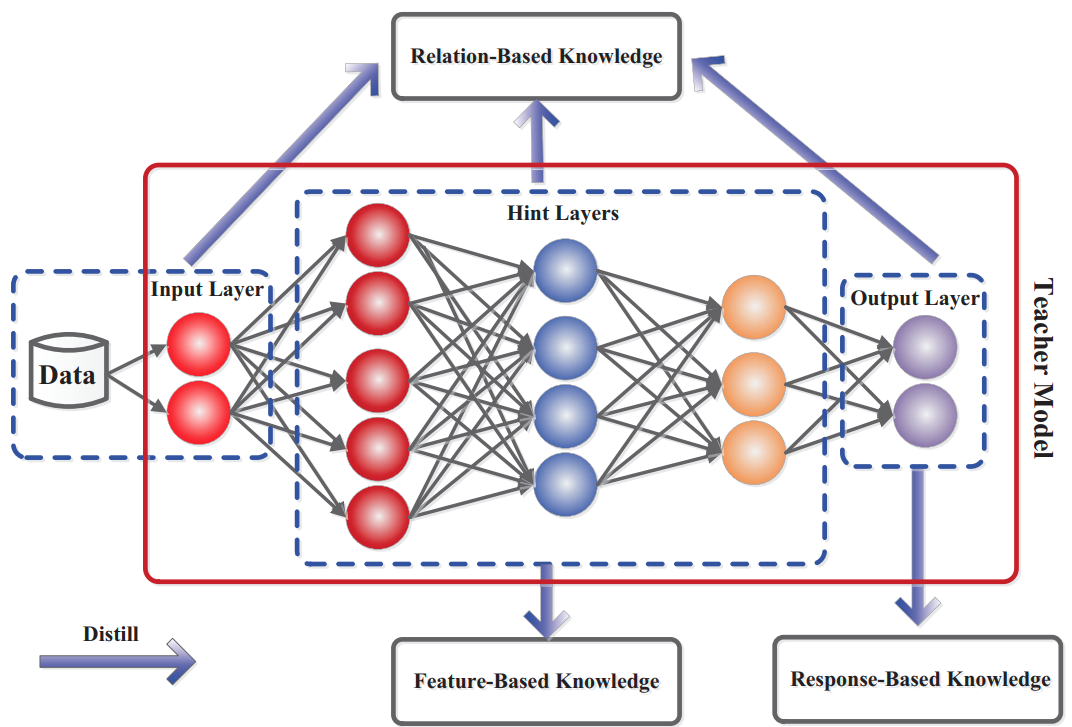
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
How Does it Work?
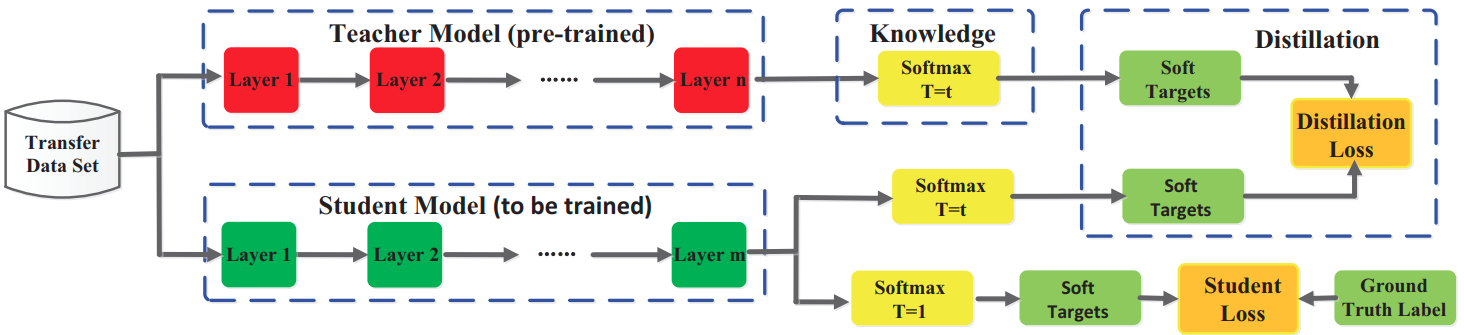
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Distilling Final Feature

- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Distilling Intermediate Features
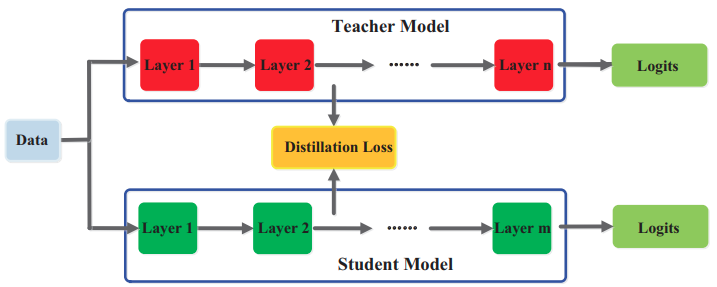
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Student Model Design
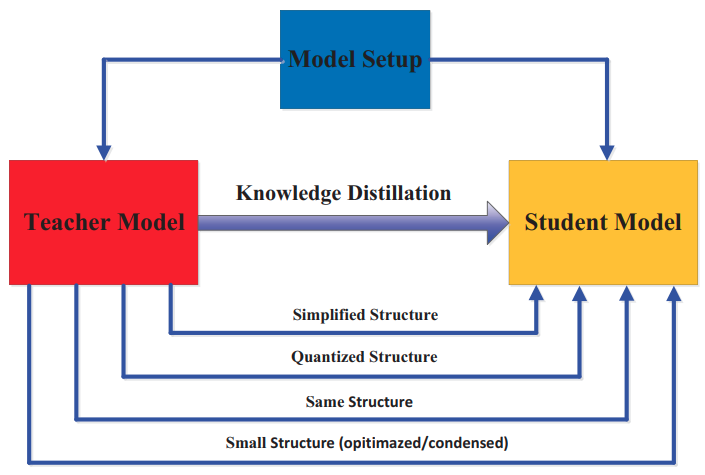
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Online and Self Distillation
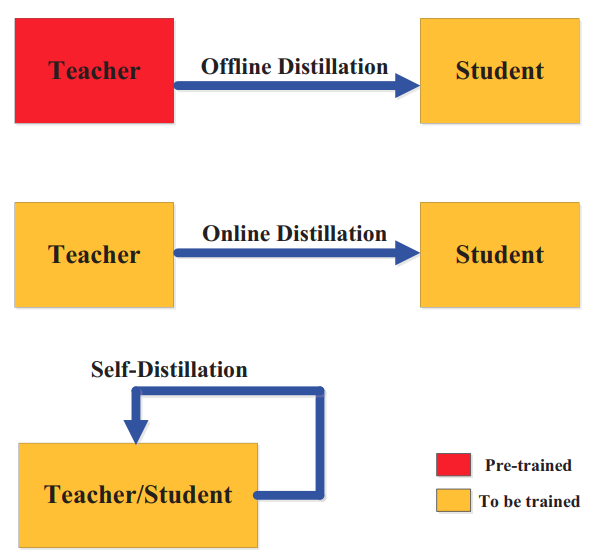
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Adversarial Knowledge Distillation
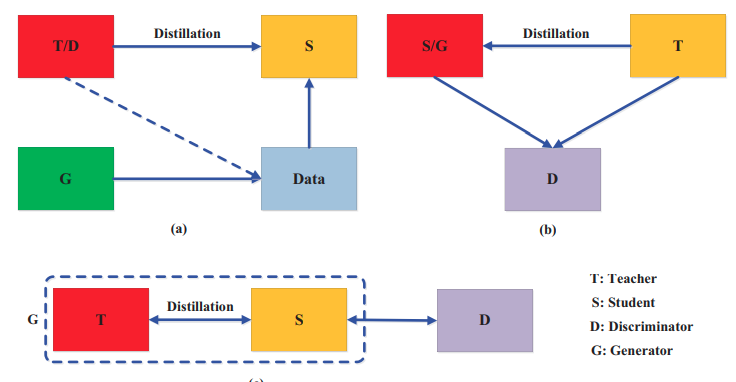
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Distillation from Teacher Ensemble
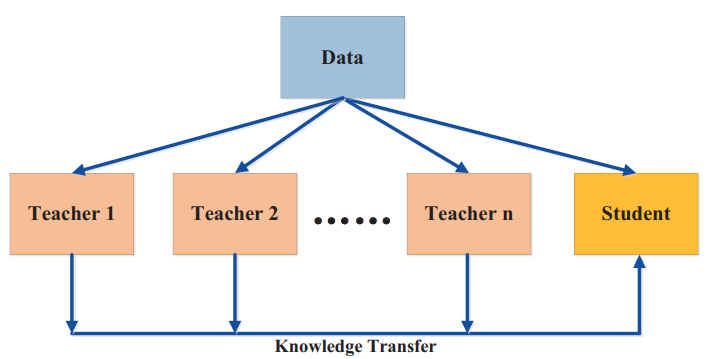
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Distillation from Teacher Ensemble
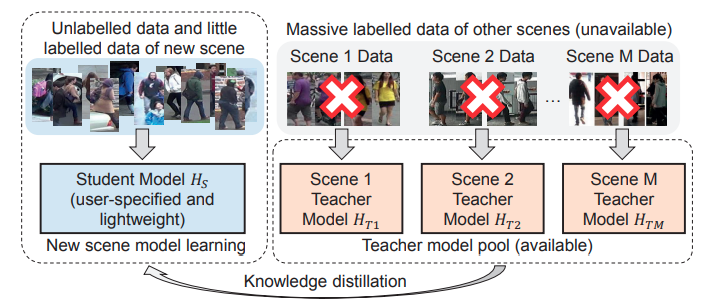
- Wu et al "Distilled Person Re-identification: Towards a More Scalable System" CVPR 2019
Knowledge for Domain Adaptation
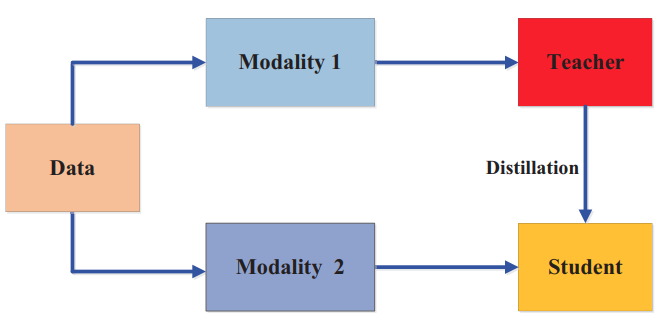
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Knowledge for Synthetic Data
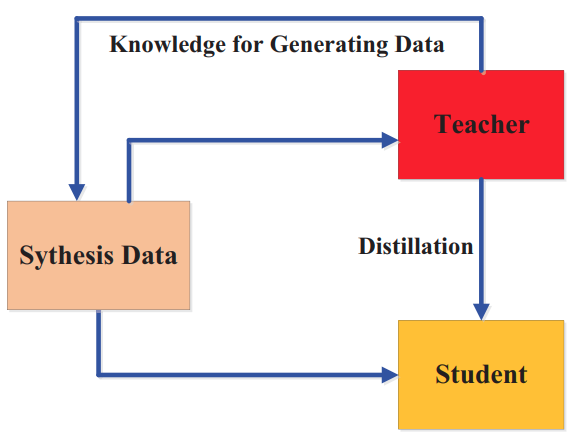
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Knowledge for Synthetic Data

- Yin et al "Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion" CVPR 2020
Model Quantization
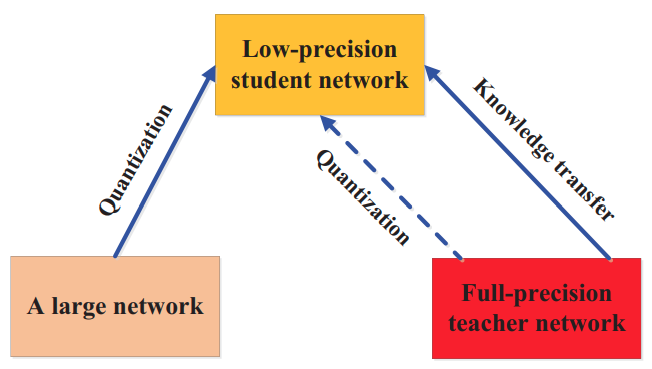
- Gou et al "Knowledge Distillation: A Survey" Arxiv 2006.05525
Model Quantization

- Kim et al "QKD: Quantization-aware Knowledge Distillation" Arxiv 1911.12491
Feature Normalized Knowledge Distillation

- Xu et al "Feature Normalized Knowledge Distillation for Image Classification" ECCV 2020
Knowledge Distialltion for Privacy Preserving Learning

- Papernot et al "Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data", ICLR 2017
Distilling Relational Knowledge
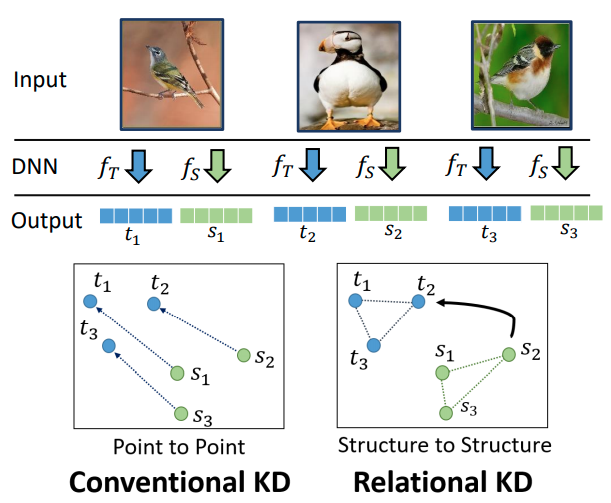
- Park et al "Relational Knowledge Distillation" CVPR 2019
Knowledge Distialltion: Black Magic?
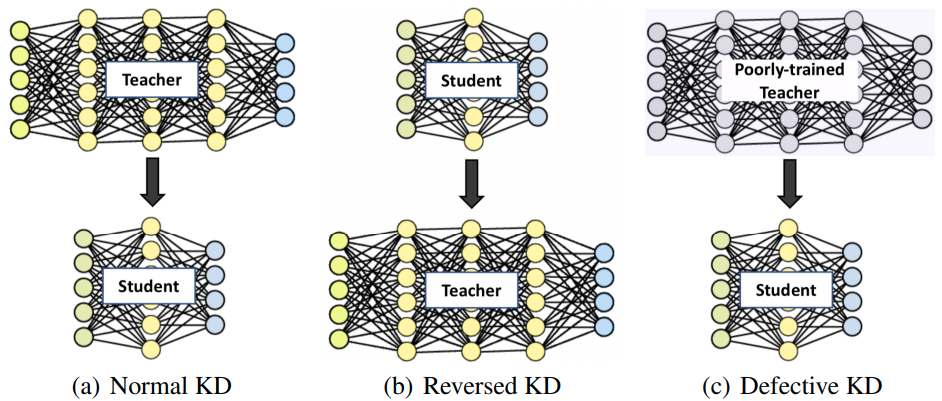
- Yuan et al "Revisiting Knowledge Distillation via Label Smoothing Regularization", CVPR 2020
Label Smoothing
$y_c^{LS} = (1-\alpha)y_c + \alpha\frac{1}{C}$
- With label smoothing, the model is encouraged to treat each incorrect class as equally probable.
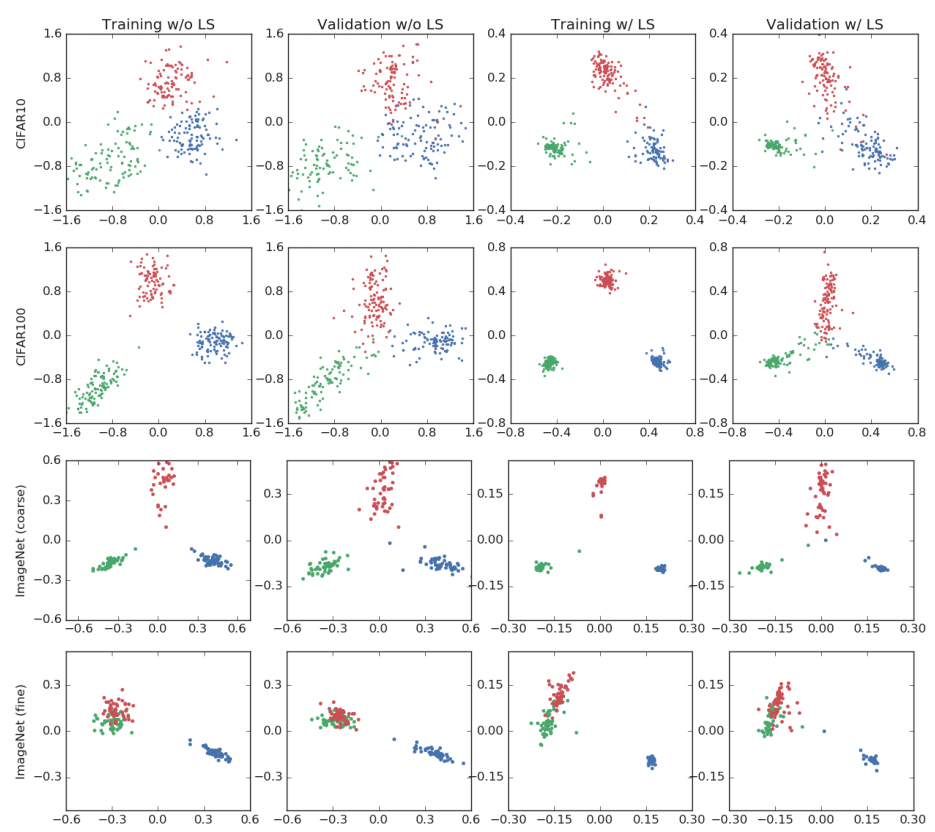
- Muller et al "When Does Label Smoothing Help?" NeurIPS 2019