Self-Supervised Learning
CSE 891: Deep Learning
Monday November 29, 2021
Success story of supervision: Pre-training
- Features from networks pre-trained on ImageNet can be used for a variety of different downstream tasks
- Pre-train on a large supervised dataset.
- Collect a dataset of "supervised" images
- Train a ConvNet
The promise of "alternative" supervision
- Getting "real" labels is difficult and expensive
- ImageNet with 14M images took 22 human years.
- Obtain labels using a "semi-automatic" process
- Hashtags
- GPS locations
- Using the data itself: "self"-supervised
Can we get labels for all data?
- Datasets we have:
- Bounding Boxes: $10^6$
- Image Level: $10^7$
- Internet Photos: $10^{13}$
- Real World: $10^{20}$?
- What about complex concepts?
- Video?
- Labelling cannot scale to the size of the data we generate
"Self"-Supervision
- Key Idea:
- Obtain "labels" from the data itself by using a "semi-automatic" process
- Predict part of the data from other parts
- Observed Data $\rightarrow$ Hidden data
- Observed Data $\rightarrow$ Hidden property of data
- Why self-supervision?
- Helps us learn using observations and interactions
- Does not require exhaustive annotation of concepts
- Leverage multiple modalities or structure in the domain
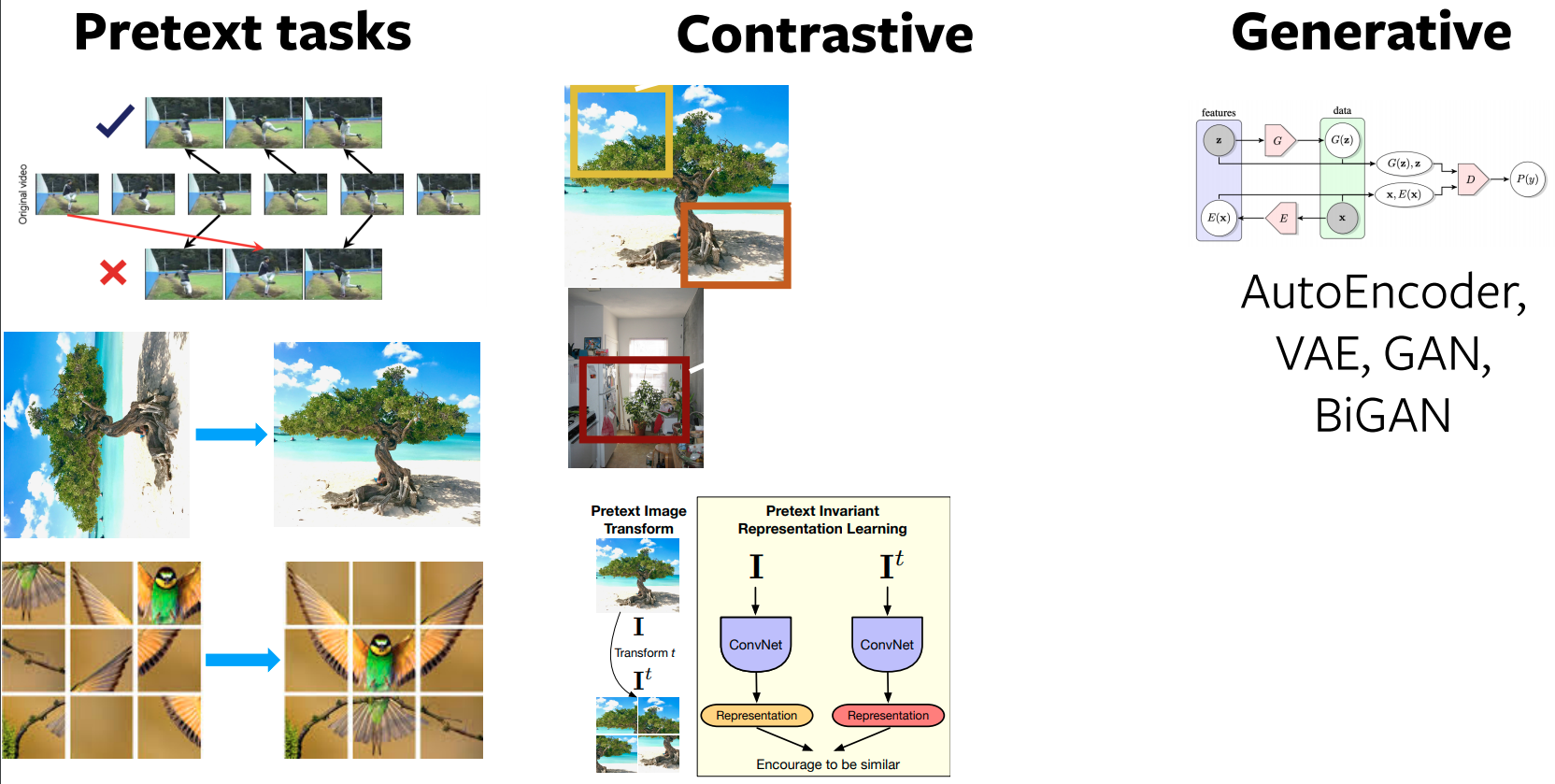
Pretext Task
- Self-supervised task used for learning representations
- Often, not the "real" task (like image classification) we care about
- What kind of pretext tasks?
- Using images
- Using video
- Using video and sound
- $\dots$
- Doersch et al., 2015, Unsupervised visual representation learning by context prediction, ICCV 2015
Images: Relative Position of Patches

- Doersch et al., 2015, Unsupervised visual representation learning by context prediction, ICCV 2015
Images: Relative Position: Nearest Neighbors in features

- Doersch et al., 2015, Unsupervised visual representation learning by context prediction, ICCV 2015
Images: Predicting Rotations

- Gidaris et al, Unsupervised Representation Learning by Predicting Image Rotations, ICLR 2018
Image: Colorization
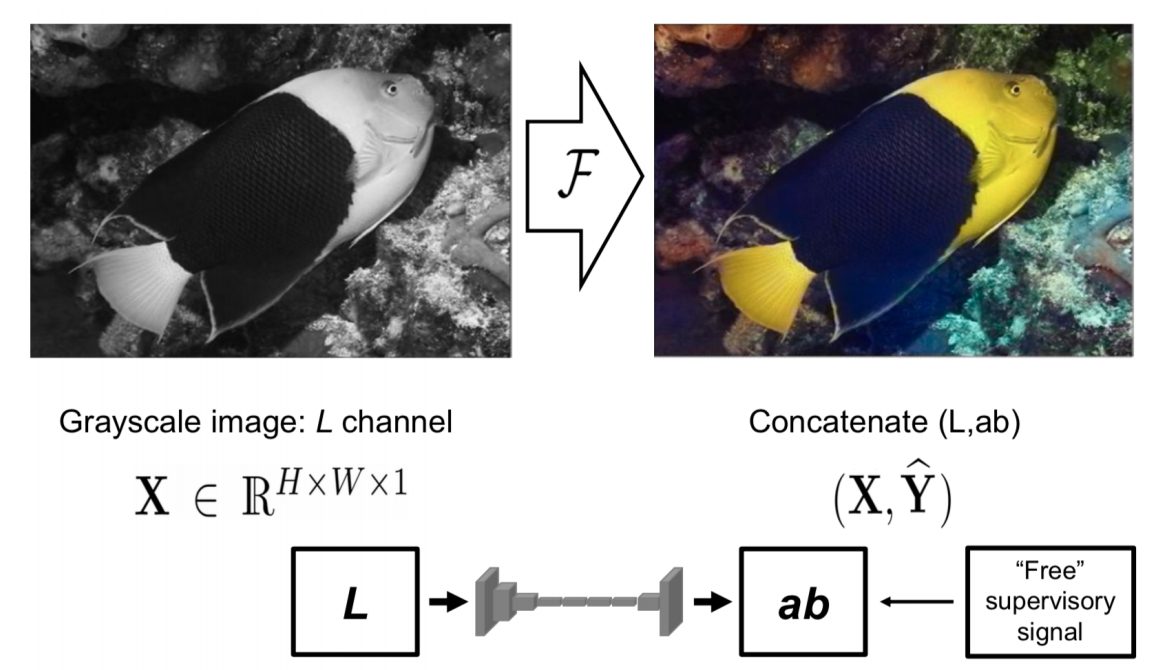
- Zhang et. al, Colorful Image Colorization, ECCV 2016
Image: Fill in the Blanks

- Pathak et al, Context Encoders: Feature Learning by Inpainting, CVPR 2016
Video
- Video is a "sequence" of frames
- How to get "self-supervision"?
- Predict order of frames
- Fill in the blanks
- Track objects and predict their position
Videos: Shuffle and Learn
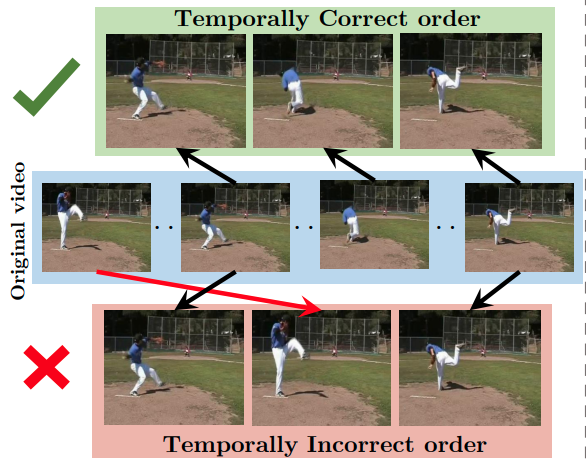
- Misra et al, Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016
Videos: Shuffle and Learn
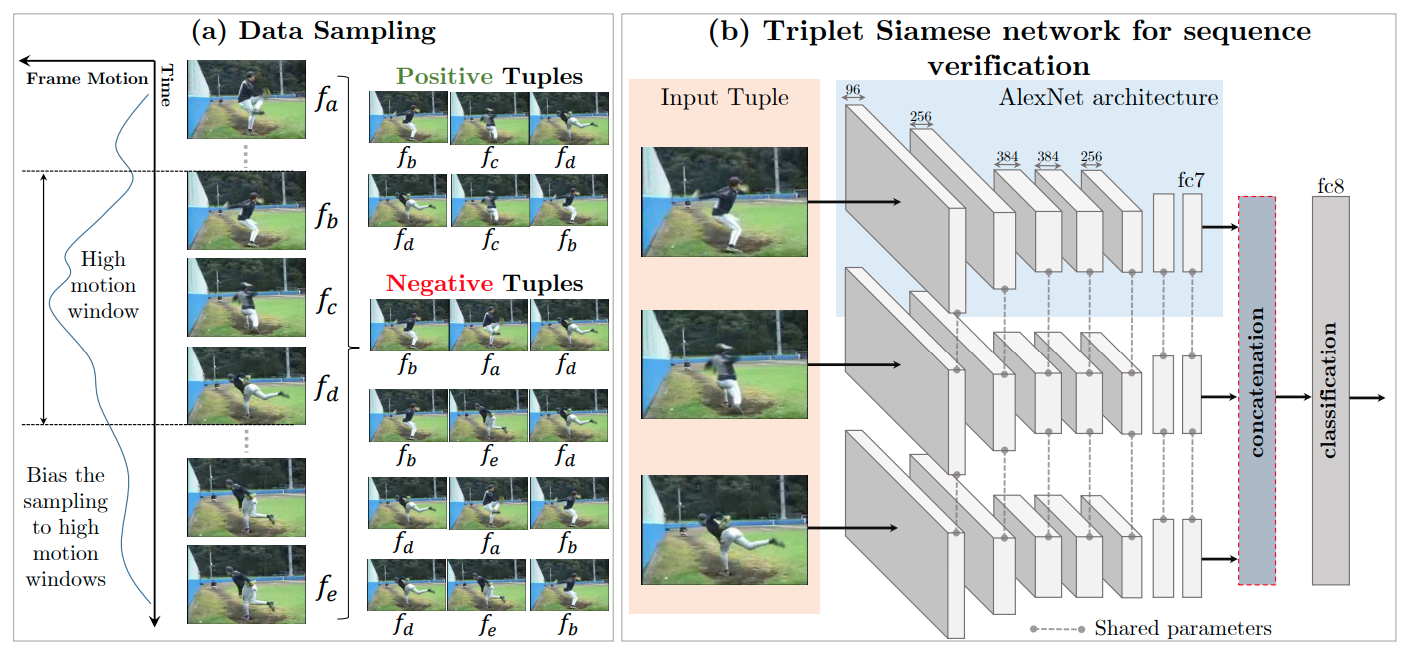
- Misra et al, Shuffle and Learn: Unsupervised Learning using Temporal Order Verification, ECCV 2016
Videos: Shuffle and Learn
- Fine-tune on Human Keypoint Estimation
| Intialization (ALexNet) | ||
|---|---|---|
| FLIC (AUC) | MPII (AUC) | |
| ImageNet Supervised | 51.3 | 47.2 |
| Shuffle & Learn (self-supervised) | 49.6 | 47.6 |
Videos: Odd-one-Out Networks
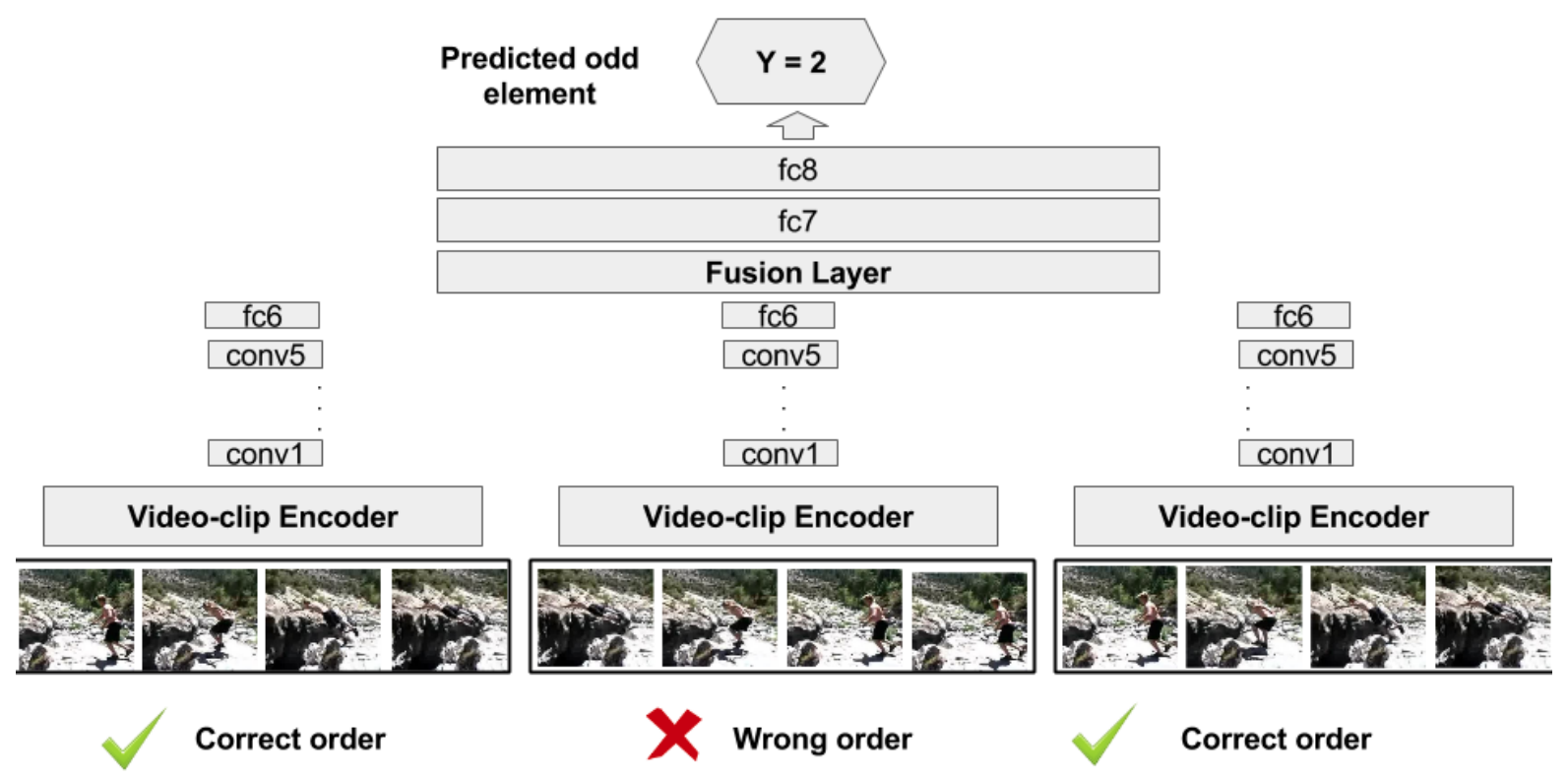
- Fernando et al, Self-Supervised Video Representation Learning With Odd-One-Out Networks, CVPR 2017
Audio-Video Co-Supervision
- Train a network to predict if "image" and "audio clip" correspond

- What can be learnt?
- Good representations – Visual features – Audio features
- Intra- and cross-modal retrieval – Aligned audio and visual embeddings
- “What is making the sound?” – Learn to localize objects that sound
- Arandjelović, Objects that Sound, ECCV 2018
Audio-Video Co-Supervision
- Train a network to predict if "image" and "audio clip" correspond

- Arandjelović, Objects that Sound, ECCV 2018
Audio-Video Co-Supervision
- What would make this sound?
- No video (motion) information is used.

- Arandjelović, Objects that Sound, ECCV 2018
Understanding what the "pretext" task learns
- Are they complementary?
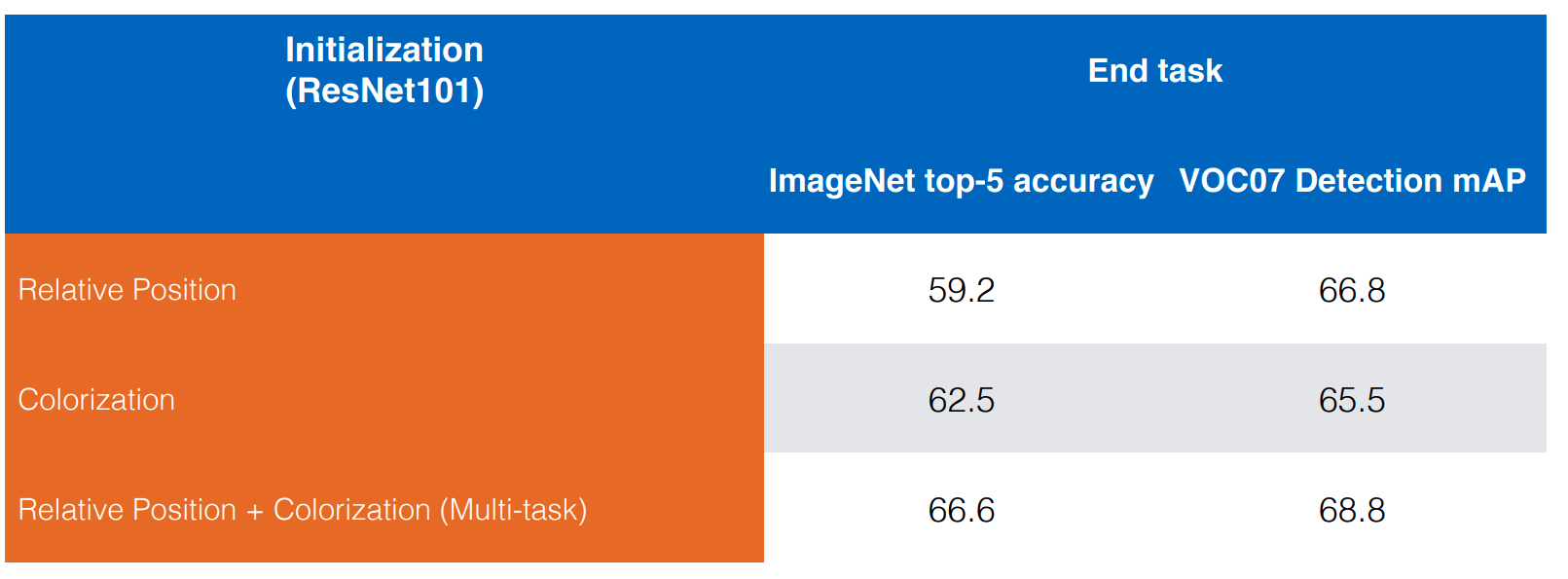
- Doersch, Multi-task Self-Supervised Visual Learning, ICCV 2017
Information predicted: varies across tasks
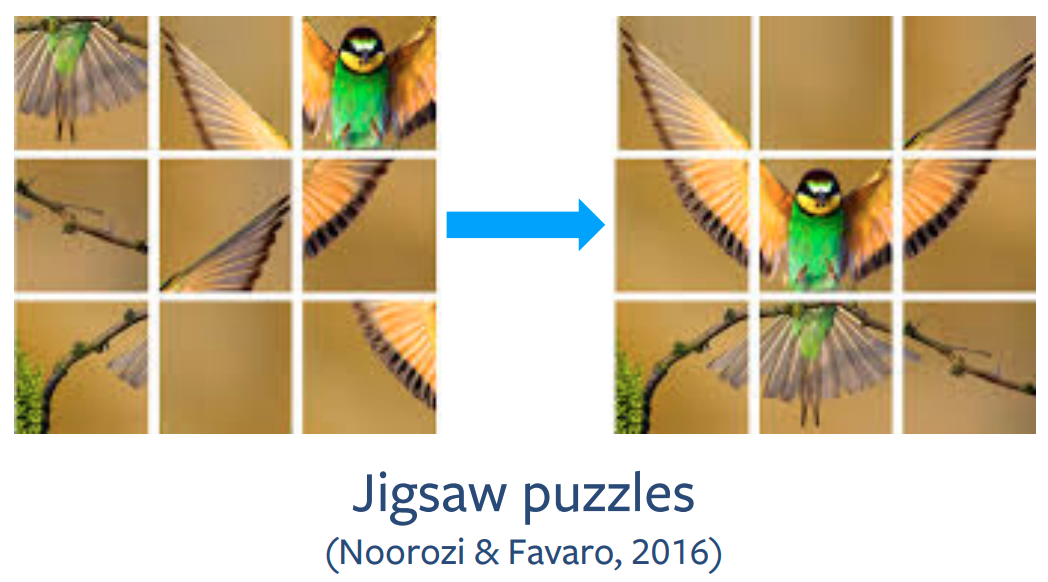
Scaling Self-Supervised Learning
- Doersch, Multi-task Self-Supervised Visual Learning, ICCV 2017
Scaling Self-Supervised Learning

- Use $N=9$ patches
- In practice, use a subset of permutations
- E.g., 100 from 9!
- Each patch is processed independently
- N-way ConvNet (shared params)
- Problem Complexity: size of subset
Evaluation - fine-tuning vs. linear classifier

- A good representation transfers with little training
Evaluation - Many Tasks

Evaluation: Image Classification
- Extract "fixed" features
- Train a Linear SVM on fixed features
- Use VOC 2007 image classification tasks

Evaluation: Object Detection
| Intialization | ||
|---|---|---|
| PASCAL VOC 2007 | PASCAL VOC 2007+2012 | |
| ImageNet Supervised | 70.5 | 76.2 |
| Jigsaw ImageNet 14M | 69.2 | 75.4 |
Evaluation: Surface Normal Estimation
| Intialization | Median Error | % correct withing $11.25^0$ |
|---|---|---|
| ImageNet Supervised | 17.1 | 36.1 |
| Jigsaw Flickr 100M | 13.1 | 44.6 |
Evaluation: Few-Shot Learning

What does each layer learn?
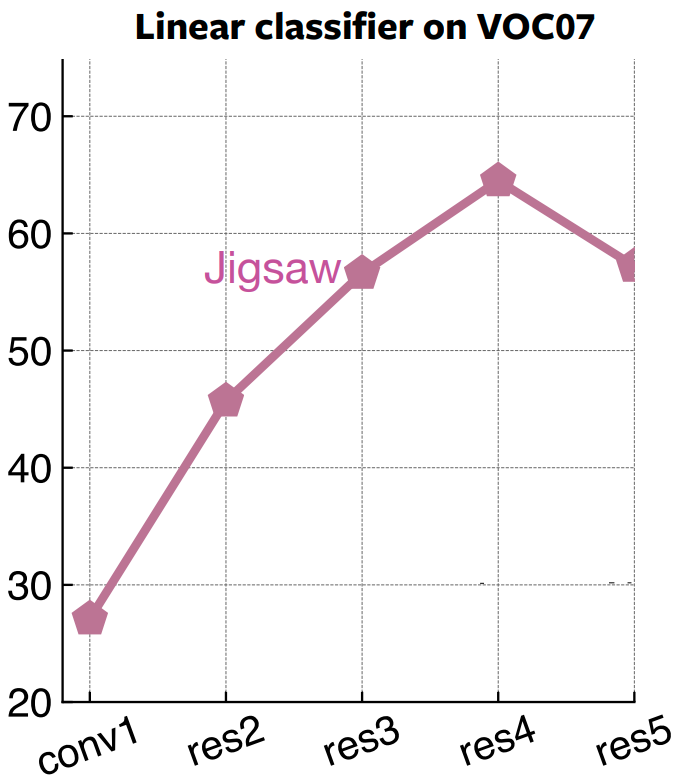
- Higher layers do not generalize.
- Problem:
- pretext tasks do not teach about semantics
- performing a non semantic tasks does not produce good features
What should pre-trained features learn?
- Represent how images relate to one another
- Be robust to "nuisance factors" -- Invariance
- e.g., exact location of objects, lighting, exact color
- Clustering and Contrastive Learning are two ways to achieve the above.
Clustering
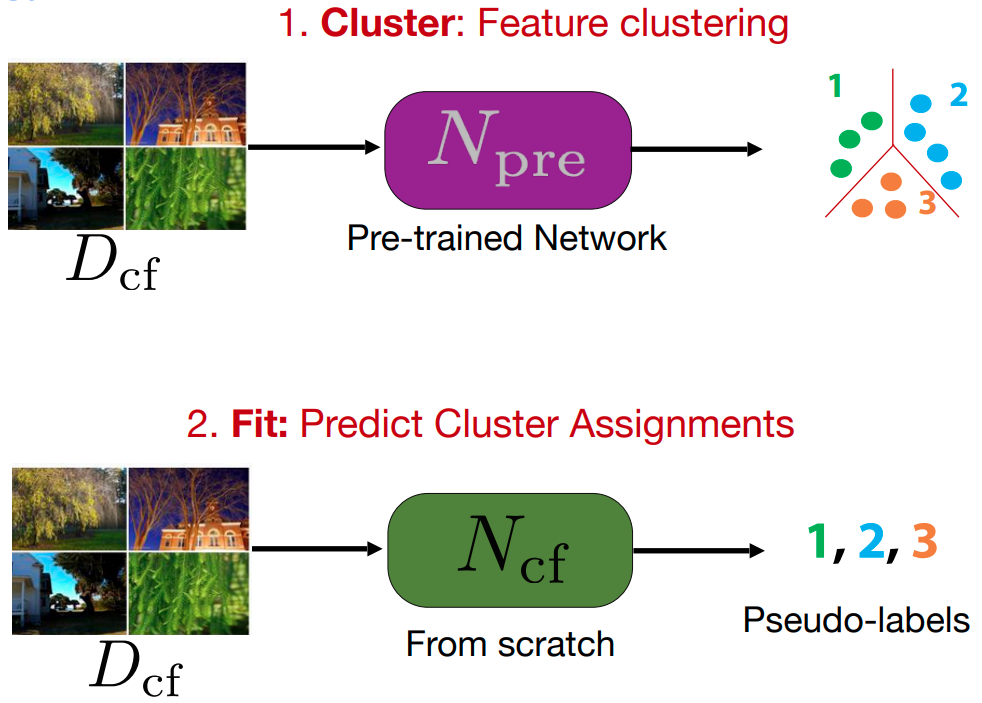
- Boosting Knowledge (Noroozi et al., 2018); DeepCluster (Caron et al., 2018); DeeperCluster (Caron et al., 2019), ClusterFit (Yan et. al., 2020)
Evaluation: Synthetic Noise
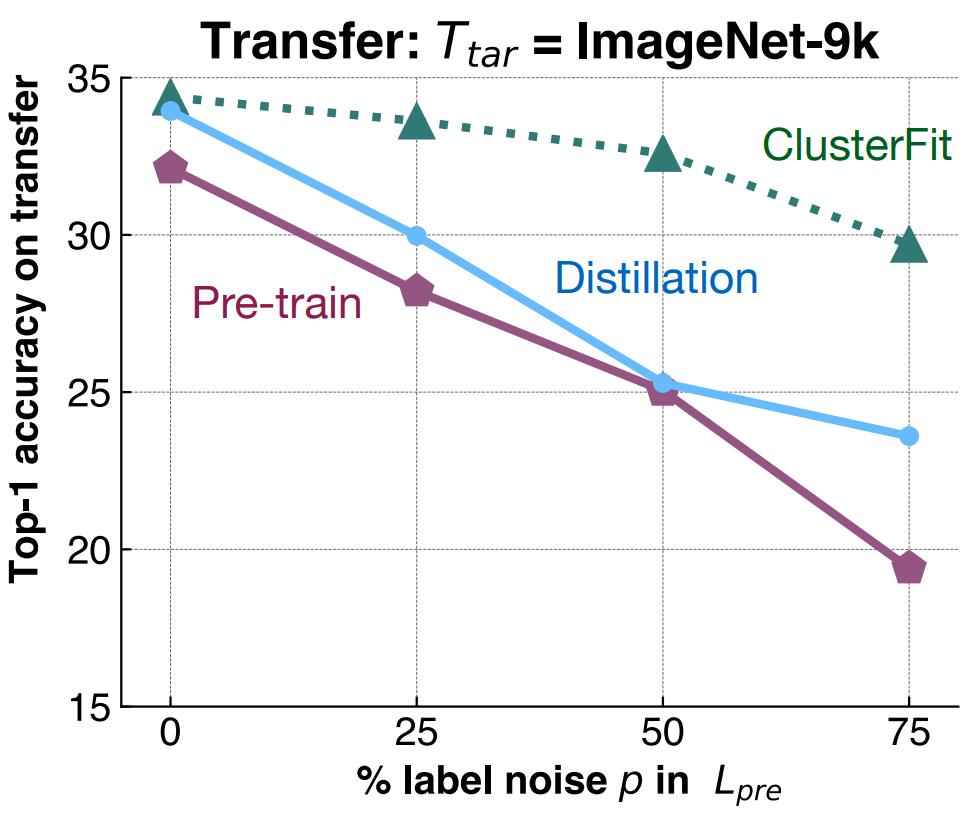
Evaluation: Self-Supervised Images

Contrastive Learning
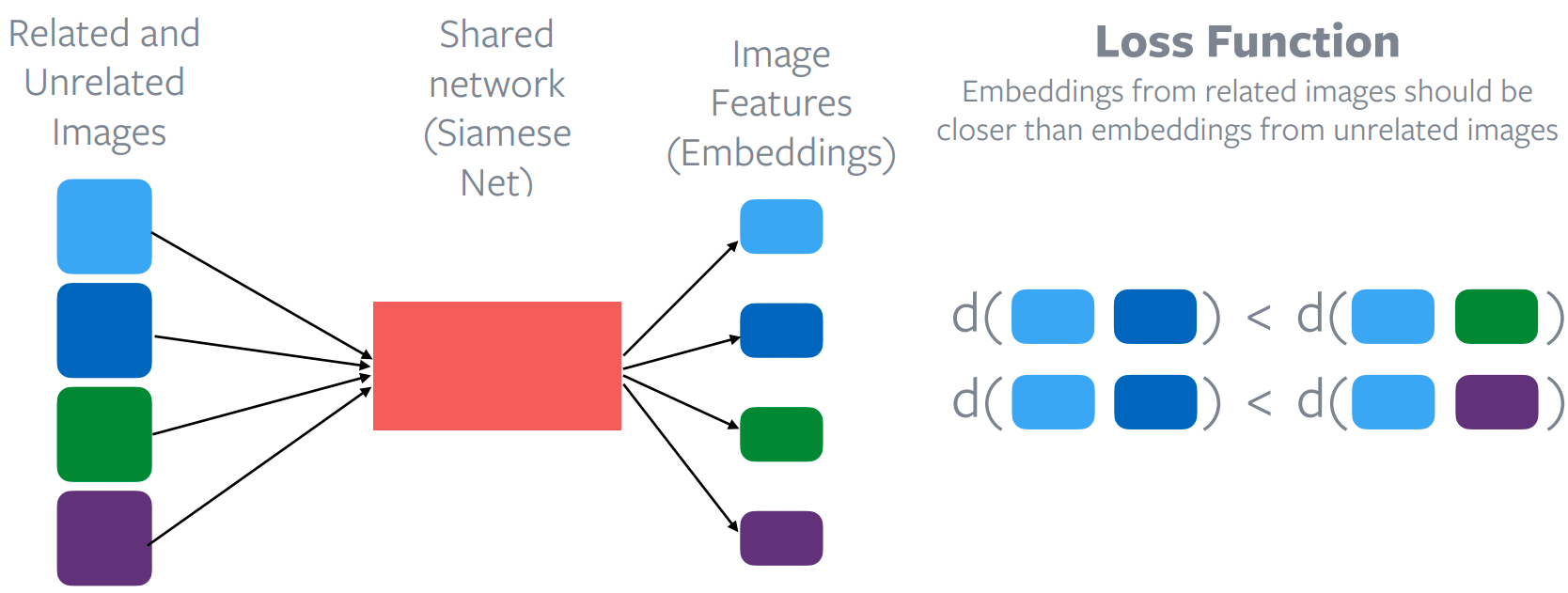
- Hadsell et. al., Dimensionality Reduction by Learning an Invariant Mapping, CVPR 2006
Contrastive Learning for Self-Supervised Learning
- How to define what images are "related" and "unrelated"?
- Nearby patches vs. distant patches of an Image
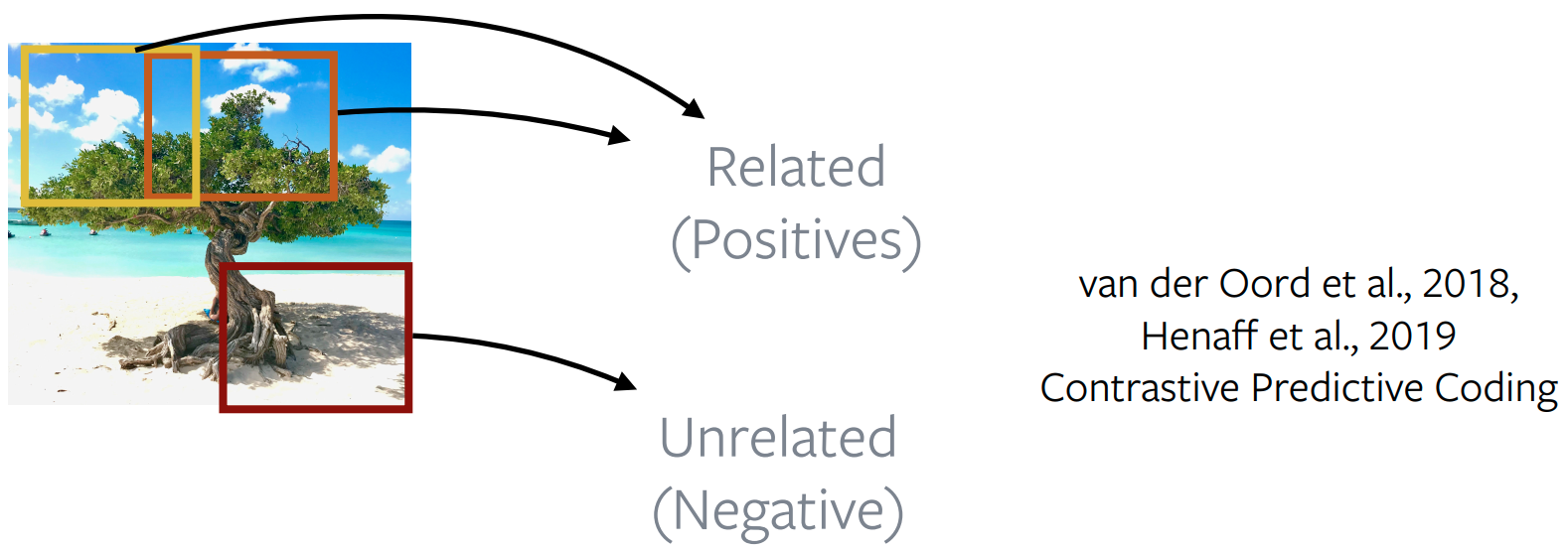
Contrastive Learning for Self-Supervised Learning
- How to define what images are "related" and "unrelated"?
- Patches of an image vs. patches of other images

Contrastive Learning for Self-Supervised Learning
- How to define what images are "related" and "unrelated"?
- Data Augmentations of each patch

Pretext-Invariant Representation Learning (PIRL)

- Be invariant to $\mathbf{t}$
- Representation contains no information about $\mathbf{t}$
- Use a contrastive loss to enforce similarity of features \begin{equation} L_{contrastive}(\mathbf{v}_{\mathbf{I}},\mathbf{v}_{\mathbf{I}^t}) \end{equation}
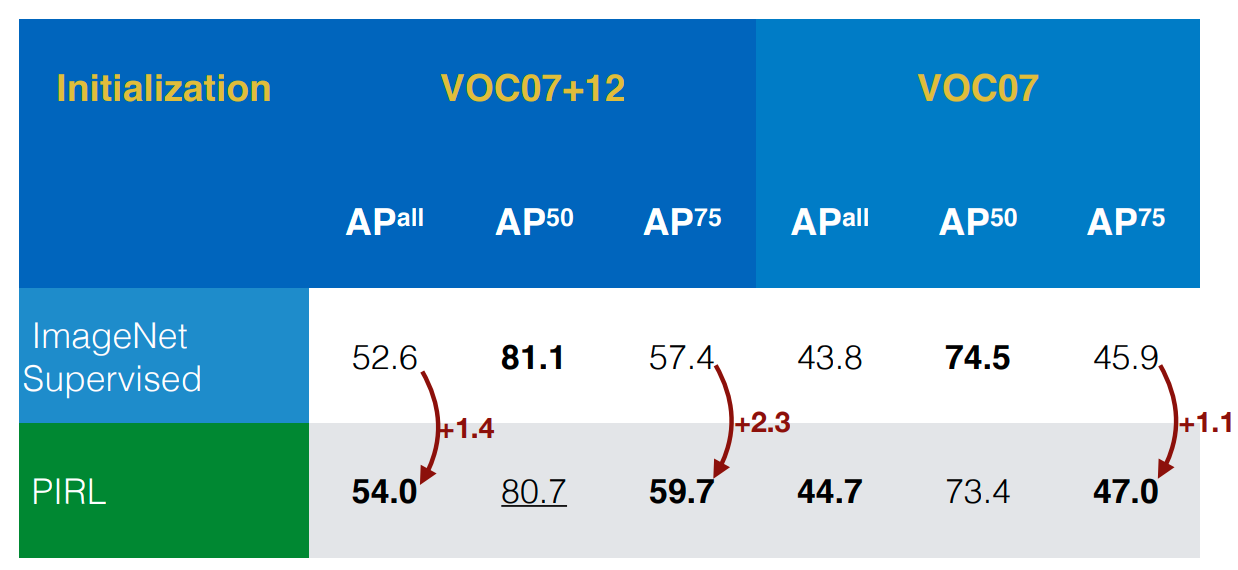
PIRL: Object Detection
- Outperforms ImageNet supervised pre-trained networks
- Full fine-tuning, no bells & whistles
PIRL: Semi-Supervised Learning
- Fine-tune on a fraction of labeled data from ImageNet-1K

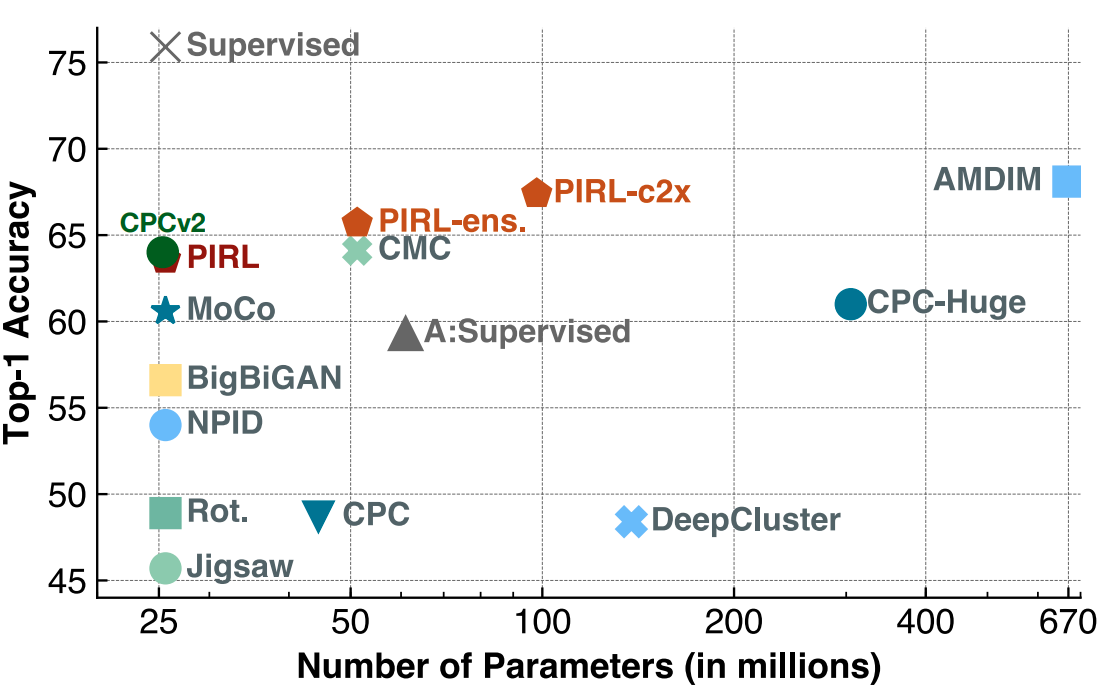
PIRL: Linear Classification
- Linear classifiers on fixed features. Evaluate on ImageNet-1K
PIRL: "In-the-wild" Flickr Images
- Yahoo Flickr Creative Commons (YFCC) images. No labels.
- Linear classifiers on fixed features

PIRL: Semantic Features?

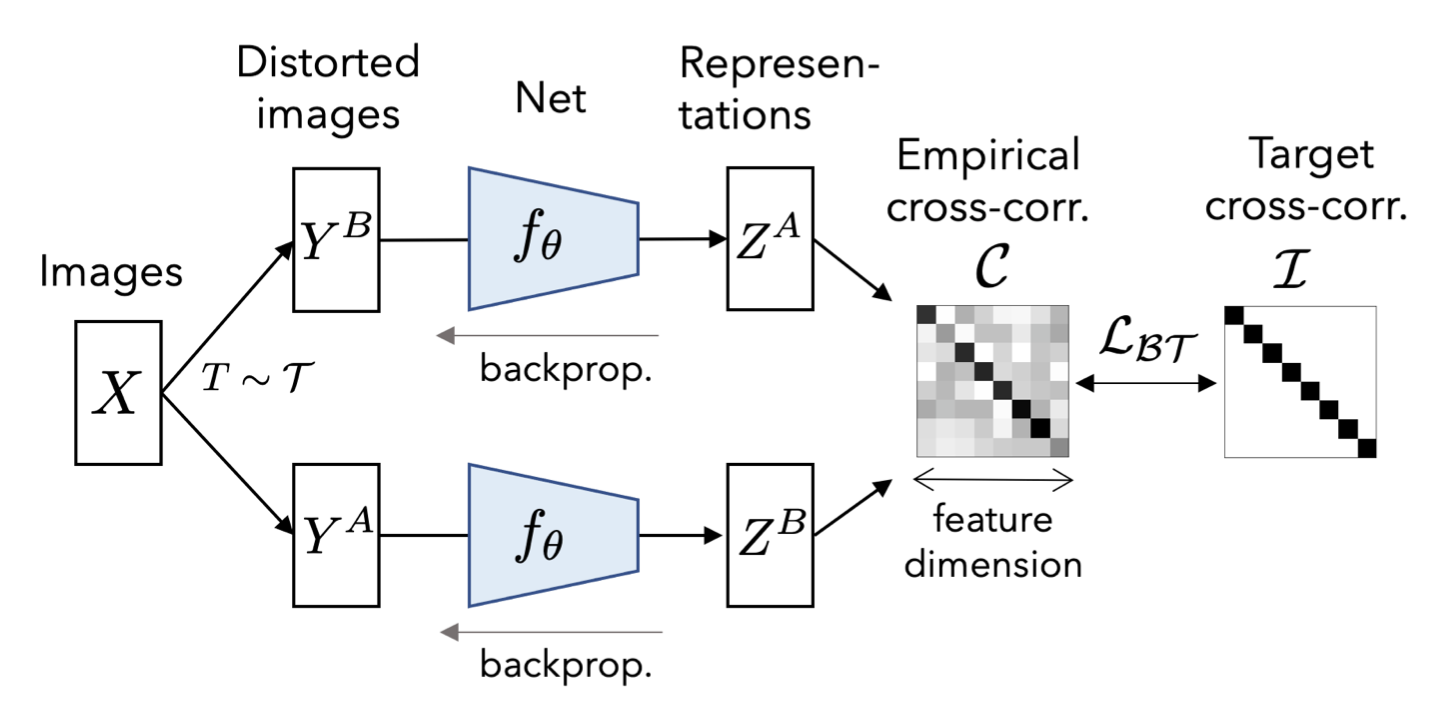
Barlow Twins
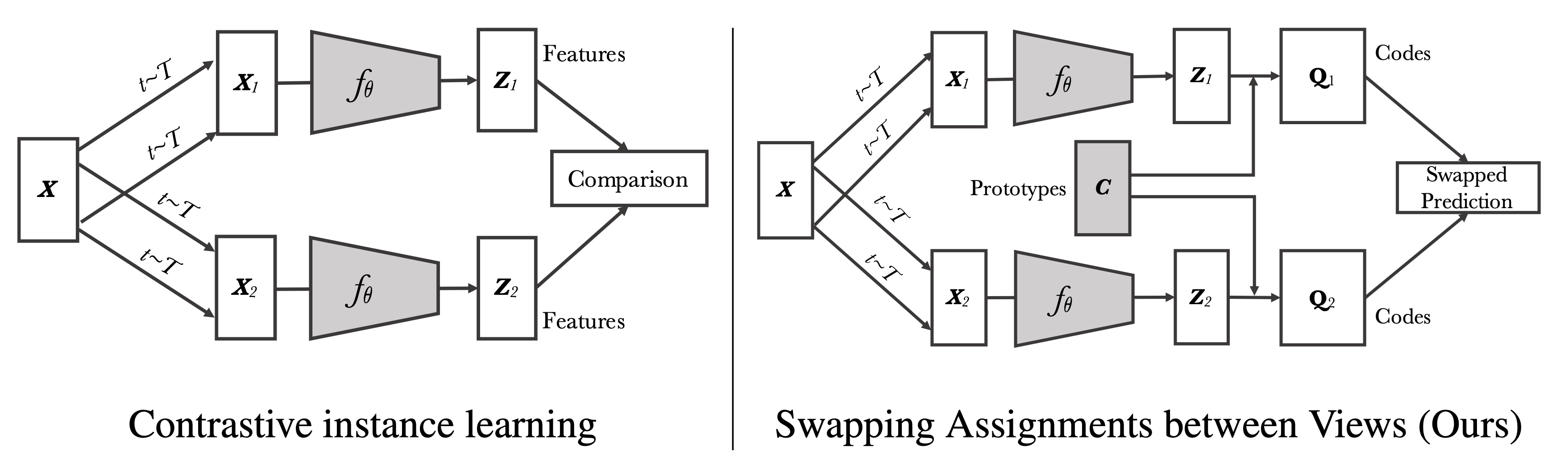
SwAV
CLIP

Key Observations of Current State-of-the-Art
- Combining multiple pretext tasks improves performance
- Larger models improve quality of representation
- Larger amounts of data improves quality of representation
- Heavy data augmentation helps, especially random crops and random colors
- Large batch size is necessary, especially for in-batch negative sampling.
- Hard negative mining for finding good negative pairs.
Summary
- Exciting new area of research for representation learning without labels.
- Use "proxy" or "pretext" tasks instead of human labels.
- Contrastive Learning is the current state-of-the-art.
- Shortcomings:
- Set of data transforms matters a lot
- What invariances matter?
- Beginning to outperform performance from supervised learning.