NLP and Transformers
CSE 891: Deep Learning
Today
- Attention
- Transformer
- NLP
Recap: Attention Layer
- Inputs:
- Query Vector: $\mathbf{q} \in \mathbb{R}^{d}$
- Input Vector: $\mathbf{X} \in \mathbb{R}^{n \times d}$
- Similarity Function: $f_{att}(\cdot)$
- Computation:
- Keys: $\mathbf{K}=\mathbf{W}_k\mathbf{X}$
- Similarities: $\mathbf{E}=f_{att}(\mathbf{K},\mathbf{Q})$, $\mathbf{e}\in\mathbb{R}^{n\times n}$
- Attention Weights: $\mathbf{A}=softmax(\mathbf{E})$, $\mathbf{A}\in\mathbb{R}^{n \times n}$
- Values: $\mathbf{V}=\mathbf{W}_v\mathbf{X}$
- Output Vector: $\mathbf{y}_j=\sum_{i=1}^n A_{ij}\mathbf{v}_i$, $\mathbf{y}\in\mathbb{R}^{d}$






Recap: Self-Attention Layer
- Inputs:
- Query Vector: $\mathbf{X} \in \mathbb{R}^{n\times d}$
- Input Vector: $\mathbf{X} \in \mathbb{R}^{n \times d}$
- Parameters: $\mathbf{W}_k \in \mathbb{R}^{d \times d'}$, $\mathbf{W}_q \in \mathbb{R}^{d \times d'}$, $\mathbf{W}_v \in \mathbb{R}^{d \times d'}$
- Similarity Function: $f_{att}(\mathbf{q},\mathbf{x}_i) = \frac{\mathbf{q}^T\mathbf{x}_i}{\sqrt{d}}$
- Computation:
- Keys and Queries: $\mathbf{K}=\mathbf{W}_k\mathbf{X}$, $\mathbf{Q}=\mathbf{W}_q\mathbf{X}$
- Similarities: $\mathbf{E}=f_{att}(\mathbf{K},\mathbf{Q})$, $\mathbf{E}\in\mathbb{R}^{n\times n}$
- Attention Weights: $\mathbf{A}=softmax(\mathbf{E})$, $\mathbf{A}\in\mathbb{R}^{n \times n}$
- Values: $\mathbf{V}=\mathbf{W}_v\mathbf{X}$
- Output Vector: $\mathbf{y}_j=\sum_{i=1}^n A_{ij}\mathbf{v}_i$, $\mathbf{y}\in\mathbb{R}^{d}$






Advantages of Attention
- Significantly improves Neural Machine Translation performance.
- Allows decoder to focus on certain parts of the source.
- Solves the bottleneck problem.
- Allows decoder to look directly at source; bypass bottleneck
- Helps with vanishing gradients problem
- provides shortcut between faraway states
- Provides some intepretability
- By inspecting attention distribution, we can see what the decoder was focusing on.
Attention for Deep Learning
- Weighted sum is a selective summary of the information contained in values. Query determines which values to focus on.
- Way to obtain a fixed-size representation of an arbitrary set of representations (values) dependent on some other representation (query).
Multihead Self-Attention Layer
- Scaled Dot-Product Attention attends to one or few entries in the input key-value pairs.
- Only one way for a word to interact with others
- Humans can attend to many things simultaneously.
- Can we extend attention to achieve the same?
- Idea: apply Scaled Dot-Product Attention multiple times on the linearly transformed inputs.
- Split Inputs
- Use $H$ independent "Attention Heads" in parallel
- Concatenate Outputs



Making Attention Positional Again
- Unlike RNNs and CNNs encoders, the attention encoder outputs do not depend on the order of the inputs.
- The order of the sequence conveys important information for the machine translation tasks and language modeling.
- Idea: add positional information of a input token in the sequence into the input embedding vectors. $$\begin{equation} PE_{pos, 2i} = sin\left(\frac{pos}{10000^{\frac{2i}{d_{emb}}}}\right) \mbox{ and } PE_{pos, 2i+1} = cos\left(\frac{pos}{10000^{\frac{2i}{d_{emb}}}}\right) \end{equation}$$
- Final input embeddings are the concatenation of the learnable embedding and the positional encoding.
- Positional encoding allows same words at different locations to have different overall representations.
Manual Positional Encoding
Learned Positional Encoding
- One can learn the positional encoding instead of manually specifying it.
More Attention Variants
- Dot Product: $f_{att}(\mathbf{q},\mathbf{x}_i) = \mathbf{q}^T\mathbf{x}_i$
- Assumes key and query are of same size.
- Bilinear: $f_{att}(\mathbf{q},\mathbf{x}_i) = \mathbf{q}^T\mathbf{W}\mathbf{x}_i$
- $\mathbf{W}\in\mathbb{R}^{d_1\times d_2}$
- Allows of key and query to be of different dimensionality
- Additive: $f_{att}(\mathbf{q},\mathbf{x}_i) = \mathbf{v}^T\mbox{tanh}(\mathbf{W}_1\mathbf{q} + \mathbf{W}_2\mathbf{x}_i)$
- $\mathbf{W}_1\in\mathbb{R}^{d_3\times d_1}, \mathbf{W}_2\in\mathbb{R}^{d_3\times d_2}, \mathbf{v}\in\mathbb{R}^{d_3}$
- $d_3$ (the attention dimensionality) is a hyperparameter
- more flexible similarity function
Visualizing Attention
- Self-attention layers learned that "it" could refer to different entities in the different contexts.
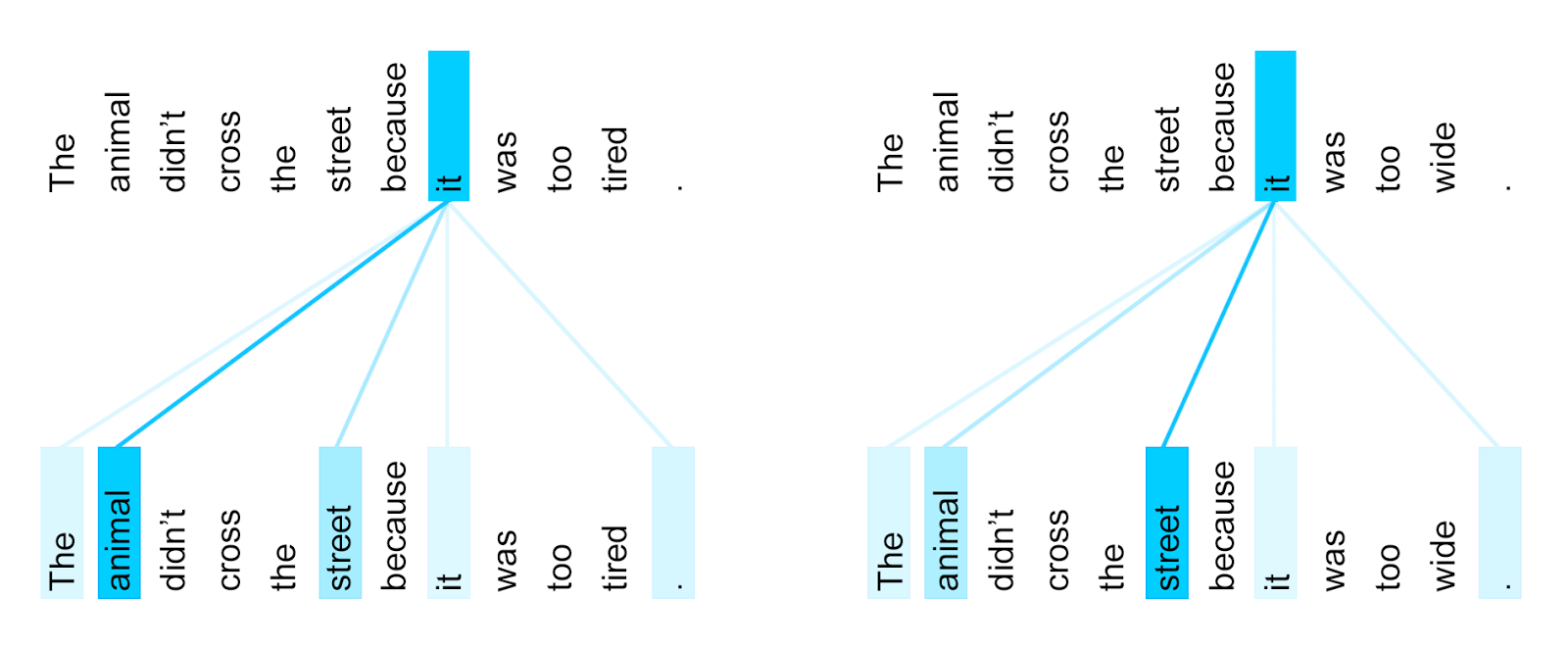
Visualizing Multi-Head Attention

Computational Cost and Parallelism
- Computational Cost:
- Complexity: How many multiply-add operations for the forward and backward pass.
- Sequential Ops: The computations that cannot be parallelized. (The part of the model that requires a for loop.)
- Maximum Path Length: the shortest path length between the first encoder input and the last decoder output.
Computational Efficiency
| Layer Type | Complexity Per Layer | Sequential Ops | Max Path Length |
|---|---|---|---|
| Self-Attention | $\mathcal{O}(n^2 \cdot d)$ | $\mathcal{O}(1)$ | $\mathcal{O}(1)$ |
| Recurrent | $\mathcal{O}(n \cdot d^2)$ | $\mathcal{O}(n)$ | $\mathcal{O}(n)$ |
| Convolutional | $\mathcal{O}(k \cdot n \cdot d^2)$ | $\mathcal{O}(1)$ | $\mathcal{O}(\log_k(n))$ |
| Self-Attention (restricted) | $\mathcal{O}(r \cdot n \cdot d)$ | $\mathcal{O}(1)$ | $\mathcal{O}(n/r)$ |
Attention is All You Need
Why Transformers?
- We want parallelization but RNNs are inherently sequential.
- Despite LSTMs, RNNs generally need attention mechanism to deal with long range dependencies.
- path length between states grows with distance otherwise
- But if attention gives us access to any state… maybe we can just use attention and don't need the RNN?
The Transformer Block
- All vectors interact with each other
- Residual Connection
- Choice of normalization: Layer normalization
- MLP independently on each vector
- Residual connection
- Output
The Transformer
- Transformer Block:
- Input: set of vectors $\mathbf{x}$
- Output: set of vectors $\mathbf{y}$
- Self-attention is the only interaction between vectors
- Layer Norm and MLP work independently per vector
- Highly scalable, highly parallelizable
- A Transformer is a sequence of transformer blocks.
- Vasawani et al: 12 blocks, $d=512$, 6 heads
- Vaswani et al, "Attention is all you need", NeurIPS 2017
How does it do?
- Vaswani et al, "Attention is all you need", NeurIPS 2017
Transformer Variants
- GPT
- Contextualize words by just using left-to-right language model
- Pre-train network to predict the next word
- ELMo
- Pretrains two language models: left-to-right and right-to-left
- Concatenate final layer output
- Only 'shallow' combination of leftward and rightward context
- BERT
- Mask 15% of tokens, and predict blanks
- All words condition on all other words
- RoBERTa
- Simplify BERT’s pre-training objective
- Scale up batch sizes, train on 1000 GPUs
- XLNet: Predict masked tokens auto-regressively in random order
- SpanBERT: Mask spans instead of tokens
- ELECTRA: Substitute tokens with similar ones, and predict which changed
- ALBERT: Tie weights across layers
- XLM: Run BERT on lots of languages
The Transformer: Transfer Learning
- "ImageNet Moment for Natural Language Processing"
- Pre-Training:
- Download a lot of text from the internet
- Train a giant Transformer model for language modeling
- Lot of objectives work well!
- Crucial to model deep, bidirectional interactions between words
- Large gains from scaling up pre-training, with no clear limits yet
- Finetuning:
- Fine-tune the Transformer on your own NLP task
- Devlin et al, "BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding", EMNLP 2018
Scaling Up Transformer
| Model | Layers | Width | Heads | Params | Data | Training |
|---|---|---|---|---|---|---|
| Transformer-Base | 12 | 512 | 8 | 65M | 8x P100 (12 hrs) | |
| Transformer-Large | 12 | 1024 | 16 | 213M | 8x P100 (3.5 days) | |
| BERT-Base | 12 | 768 | 12 | 110M | 13GB | |
| BERT-Large | 24 | 1024 | 16 | 340M | 13GB | |
| XLNet-Large | 24 | 1024 | 16 | 340M | 126GB | 512x TPU-v3 (2.5 days) |
| RoBERTa | 24 | 1024 | 16 | 355M | 160GB | 1024x V100 (1 day) |
| GPT-2 | 48 | 1600 | ? | 1.5B | 40GB | |
| Megatron-LM | 72 | 3072 | 32 | 8.3B | 174GB | 512x V100 (9 days) |
| Turing-NLG | 78 | 4256 | 28 | 17B | ? | 256x V100 |
| GPT-3 | 96 | 12288 | 96 | 175B | 694GB | ? |
| Gopher | 80 | 16384 | 128 | 280B | 10.55TB | 4096x TPUv3 (38 days) |
- Brown et al, "Language Models are Few-Shot Learners", arXiv 2020
Generated Text from GPT-3
- Title: United Methodists Agree to Historic Split
- Subtitle: Those who oppose gay marriage will form their own denomination
- Article: After two days of intense debate, the United Methodist Church has agreed to a historic split - one that is expected to end in the creation of a new denomination, one that will be "theologically and socially conservative," according to The Washington Post. The majority of delegates attending the church's annual General Conference in May voted to strengthen a ban on the ordination of LGBTQ clergy and to write new rules that will "discipline" clergy who officiate at same-sex weddings. But those who opposed these measures have a new plan: They say they will form a separate denomination by 2020, calling their church the Christian Methodist denomination. The Post notes that the denomination, which claims 12.5 million members, was in the early 20th century the "largest Protestant denomination in the U.S.," but that it has been shrinking in recent decades. The new split will be the second in the church's history. The first occurred in 1968, when roughly 10 percent of the denomination left to form the Evangelical United Brethren Church. The Post notes that the proposed split "comes at a critical time for the church, which has been losing members for years," which has been "pushed toward the brink of a schism over the role of LGBTQ people in the church." Gay marriage is not the only issue that has divided the church. In 2016, the denomination was split over ordination of transgender clergy, with the North Pacific regional conference voting to ban them from serving as clergy, and the South Pacific regional conference voting to allow them.
GPT-3: Programming by Prompt
- Poor English input: I eated the purple berries.
- Good English output: I ate the purple berries.
- Poor English input: Thank you for picking me as your designer. I’d appreciate it.
- Good English output: Thank you for choosing me as your designer. I appreciate it.
- Poor English input: The mentioned changes have done. or I did the alteration that you requested. or I changed things you wanted and did the modifications.
- Good English output: The requested changes have been made. or I made the alteration that you requested. or I changed things you wanted and made the modifications.
- Poor English input: I’d be more than happy to work with you in another project
- Poor English input: I'd be more than happy to work with you on another project.
GPT-3: Literary Style Transfer
- Topic: humor: literary parodies and homages, pastiches, style parodies.
- Parodies of the fantasy novel series Harry Potter in the style of various famous authors:
- By Ernest Hemingway:
- "It was a cold day on Privet Drive. A child cried. Harry felt nothing. He was dryer than dust. He had been silent too long. He had not felt love. He had scarcely felt hate. Yet the Dementor’s Kiss killed nothing. Death didn’t leave him less dead than he had been a second before. It wasn’t about living or dying really. It wasn’t about death. It was about the Dark Lord, his creator, his engenderer. He was not resurrected. He was created again. He was whole again in the courtyard of Malfoy Manor."
GPT-3: Literary Style Transfer
- Topic: humor: literary parodies and homages, pastiches, style parodies.
- Parodies of the fantasy novel series Harry Potter in the style of various famous authors:
- By Jane Austen:
- "It is a truth universally acknowledged, that a broken Harry is in want of a book. This he knows to his cost; pressing that wretched nose against the window of a bookstore in Diagon Alley the last thing before he goes into hiding for several years, where upon, he goes straight to Azkaban."
GPT-3: Literary Style Transfer
- Topic: humor: literary parodies and homages, pastiches, style parodies.
- Parodies of the fantasy novel series Harry Potter in the style of various famous authors:
- By Arthur Conan Doyle:
- "Harry pushed at the swinging doors of the bookshop hard, and nearly knocked himself unconscious. He staggered in with his ungainly package, his cheeks scarlet with cold and the shame of having chosen the wrong month to go Christmas shopping. The proprietor of the store, however, didn’t cast even a cursory glance at him, being far more interested in an enormous hunk of wood lying in the middle of the floor, which certainly looked like a gallows. Yes, the proprietor said to a reedy old man wearing a bowler hat and a forlorn expression that made Harry want to kick him, I can rent you such a gallows for a small fee."
Attention for Semantic Segmentation

- Zhang et al, Co-occurrent Features in Semantic Segmentation, CVPR 2019
Transformers for Object Detection
- Carion et al, End-to-end object detection with Transformers, ECCV 2020
Transformers for Object Detection
- Carion et al, End-to-end object detection with Transformers, ECCV 2020
Transformer Variants
- Lots of focus on reducing the computational complexity of transformer models.
Vision Transformer
- Adapting transformers for images.
- Matches best CNN model performance when pre-trained on external large scale dataset.
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
Vision Transformer Training and Finetuning
- Training
- Pre-train on very large dataset.
- Adam optimizer, batch size of 4096, linear learning rate warmup and decay
- Fine Tuning
- replace final MLP classification head and tune its parameters.
- fine tune with SGD+momentum
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
Vision Transformer
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
MLP-Mixer
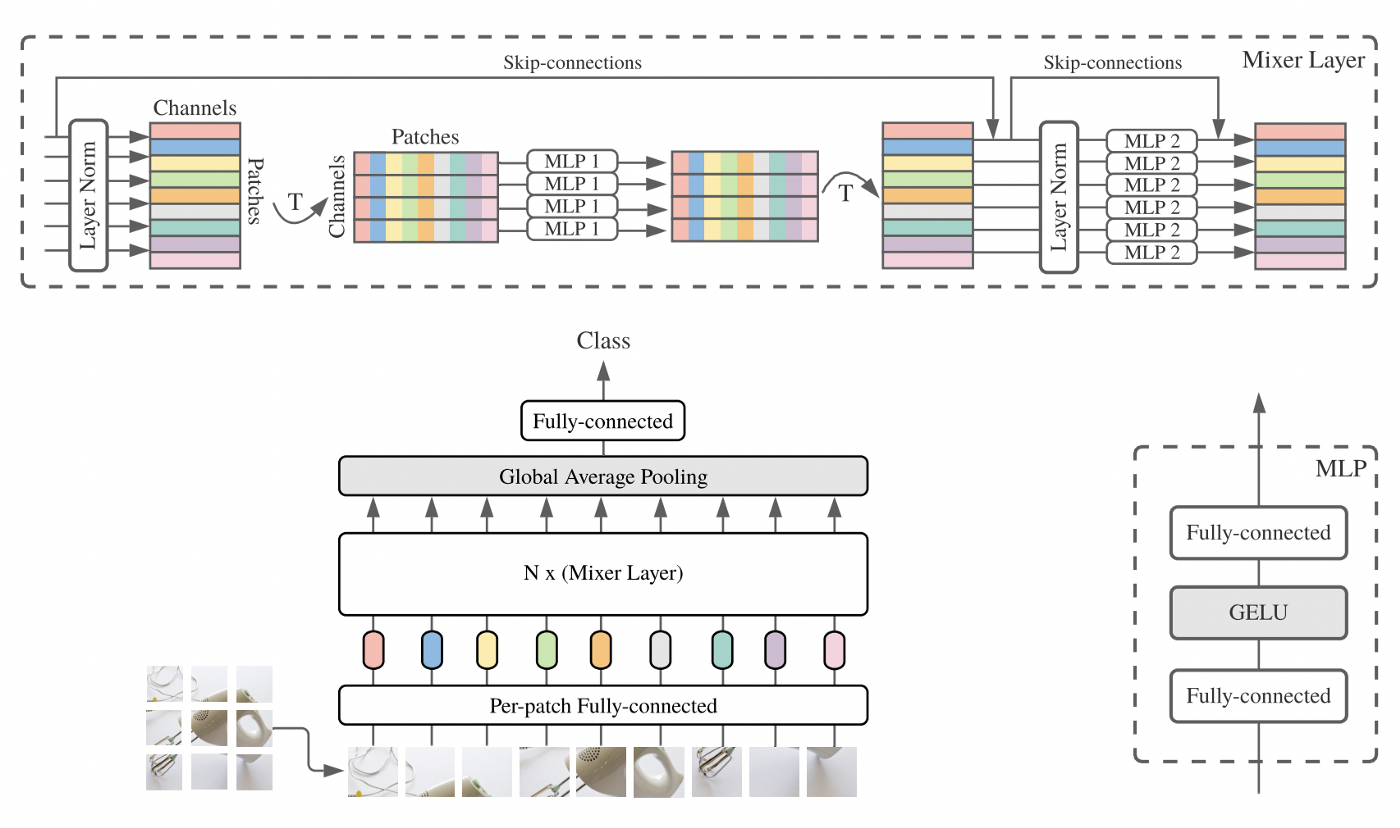
- "While convolutions and attention are both sufficient for good performance, neither of them are necessary."
- Mlp-mixer: An all-mlp architecture for vision, NeurIPS 2021
MLP-Mixer
- No pooling, operate at same size through the entire network.
- MLP-Mixing Layers:
- Token-Mixing MLP: allow communication between different spatial locations (tokens)
- Channel-Mixing MLP: allow communication between different channels
- Interleave between the layers.
- Very simple architecture.
- "In the extreme situation, our architecture can be seen as a unique CNN, which uses (1×1) convolutions for channel mixing, and single-channel depth-wise convolutions for token mixing. However, the converse is not true as CNNs are not special cases of Mixer."
- Mlp-mixer: An all-mlp architecture for vision, NeurIPS 2021
MLP-Mixer

- Mlp-mixer: An all-mlp architecture for vision, NeurIPS 2021
SWIN Transform
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, ICCV 2021 (Best Paper Award)
MetaFormer
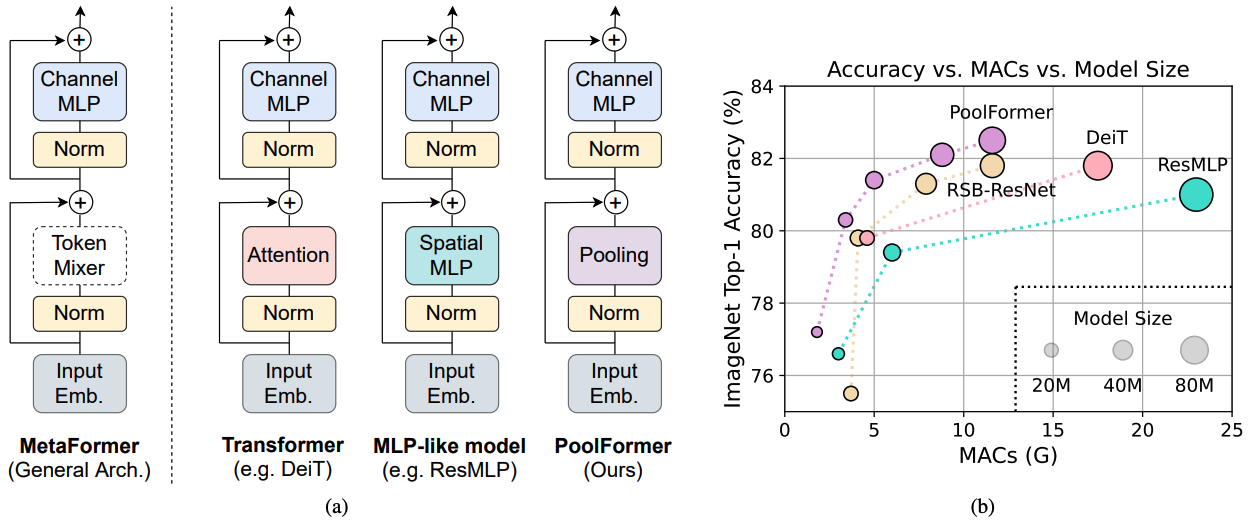
- MetaFormer Is Actually What You Need for Vision, CVPR 2022
Neighborhood Attention
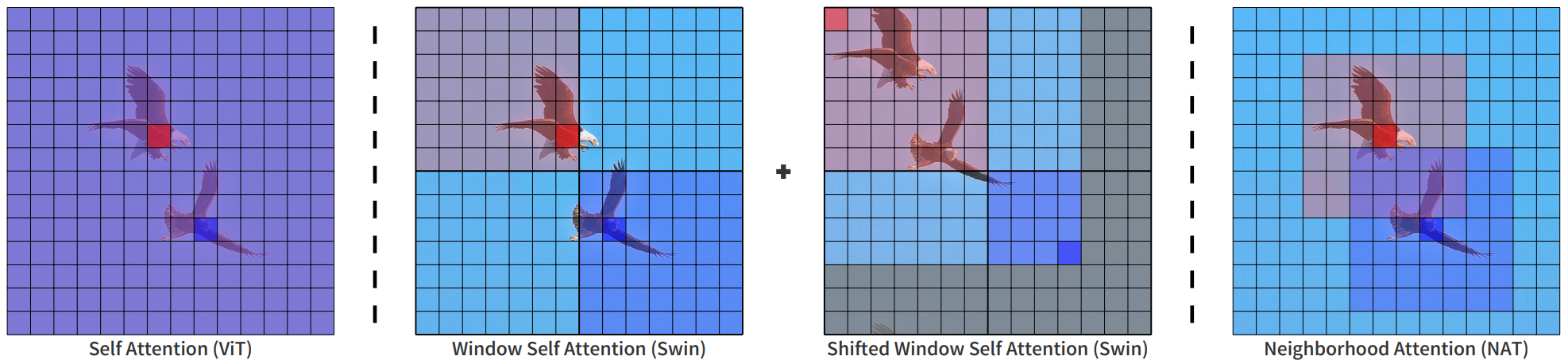

- Neighborhood Attention Transformer, ArXiv 2204.07143
- Dilated Neighborhood Attention Transformer, ArXiv 2209.15001
Summary
- Transformers are the new kid on the block over the last 1~3 years.
- The defacto architecture for NLP, CV and Multi-modal Models.
- If you can afford large data and large compute, transformers are the go to architecture, instead of CNNs, RNNs, etc.
- On our way back to fully-connected models, throwing out the inductive bias of CNNs and RNNs.
- Main benefit is speed and scalability with data.
- Dense matrix multiply is more hardware friendly than convolution, so ViTs with same FLOPs as CNNs can train and run much faster.
- Transformers have less inductive bias. So can scale much better than CNNs with data.