How to Tame Your Deep Neural Network
CSE 891: Deep Learning
Today
- Hearsay
- Hacks
- Dark Magic
Tricks of the Trade
- Before Training
- Data Augmentation
- Data Pre-Processing
- Activation Functions
- Regularization Techniques
- Intializing Model Weights
- During Training
- Learning Rate Schedules
- Large Batch Training
- Hyperparameter Optimization
- After Training
- Transfer Learning
- Ensembles
Before Training
Data Pre-Processing
- Normalize scale of data
- Data Pre-Whitening
Modern Data Processing
- Subtract the mean image (e.g. AlexNet)
- (mean image=[32,32,3] array)
- Subtract per channel mean (e.g. VGGNet)
- (mean along each channel = 3 numbers)
- Subtract per channel mean and divide by per-channel std (e.g. ResNet)
- (mean along each channel = 3 numbers)
- Not common to do PCA or whitening
Activation Functions








Activation Summary
- Things to watch out for
- Saturated neurons "kill" gradients
- Non zero-centered activations (sigmoid, relu, etc)
- Expensive computations, such as $\exp(\cdot)$
- Which activation should I use?
- Don't think too hard. Just use ReLU
- Try out Leaky ReLU/ELU/SELU/GELU if you need to squeeze that last 0.1%
- Recent architectures use GeLU instead of ReLU, but the gains are minimal.
- Smooth activations are known to be better than ReLU for adversarial robustness.
- Don't use sigmoid or tanh
Weight Initialization

- Q: What happens if we initialize all W=0, b=0?
- A: All outputs are 0, all gradients are the same! No "symmetry breaking"
- Idea: small random numbers (Gaussian with zero mean, std=0.01)
- Works okay for small networks, but does not work as well with deeper networks.
Initializing Deeper Networks
- Xavier Initialization
- normalize variance per dimension:$\sigma=1/\sqrt{n}$
- assumes zero centered activation function
- may not work well with ReLU
- Kaiming Initialization
- normalize variance per dimension:$\sigma=\sqrt{2/n}$
- ResBlock Initialization
- initialize first conv with Kaiming initializationm initialize second conv to zero
- Batch Normalization
- initialize $\gamma \sim U[0,1]$ and $\beta=0.0$

Proper Initialization
- Understanding the difficulty of training deep feedforward neural networks by Glorot and Bengio, 2010
- Exact solutions to the nonlinear dynamics of learning in deep linear neural networks by Saxe et al, 2013
- Random walk initialization for training very deep feedforward networks by Sussillo and Abbott, 2014
- Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification by He et al., 2015
- Data-dependent Initializations of Convolutional Neural Networks by Krähenbühl et al., 2015
- All you need is a good init, Mishkin and Matas, 2015
- Fixup Initialization: Residual Learning Without Normalization, Zhang et al, 2019
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Frankle and Carbin, 2019
Data Partitioning




Problem Setup
- Large Scale Training: Huge Datasets, Huge Models
- Computation on GPUs: fitting your model onto GPU
- low precision computation (float 8, float 16, float 32)
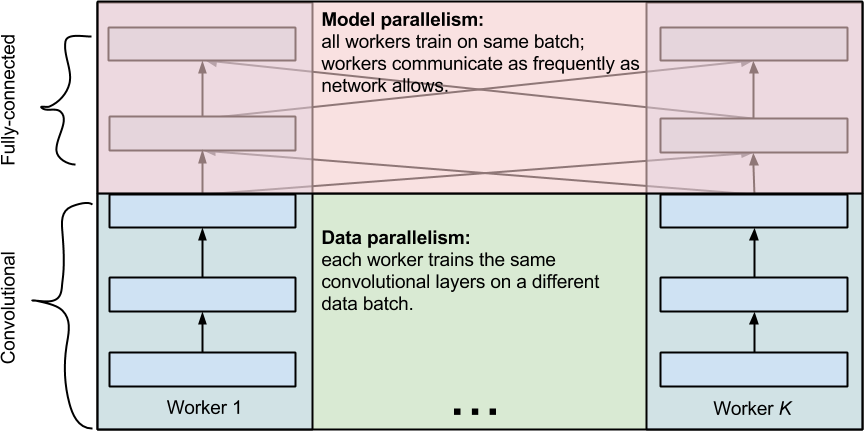
- Model Parallelism: split model across GPUs
- Handling Huge Datasets: Too much for a single GPU to process
- Data Parallelism: split data across GPUs

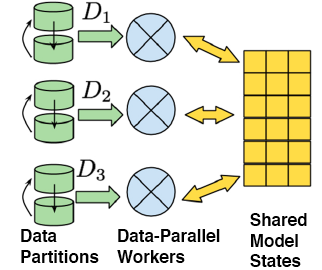
Model and Data Parallelism
During Training
Learning Rates

- Q: What is the best learning rate to use?
- A: All of them! Start with a large learning rate and decay over time.
Learning Rate Schedules
- Annealing Schedules:
- Step Decay
- Cosine Annealing
- Linear Decay
- Inverse Square Root
- Constant
- How long to train?
- Stop training the model when accuracy on the validation set decreases.
- Or train for a long time, but keep track of model snapshots that worked best on validation dataset. Always do this, even if you do not want to.
Choosing Hyperparameters
- Grid Search
- Random Search
- Bayesian Optimization
- Evolutionary Algorithms
Debugging
- Q: How do you debug your model?













Regularization
- $L_1$ regularization: $\lambda_1\|w\|_1$
- $L_2$ regularization: $\lambda_2\|w\|_2$
- $L_1+L_2$ regularization: $\lambda_1\|w\|_1 + \lambda_2\|w\|_2$
- Max-norm: $\lambda_2\|w\|_2 \leq c$
- MaxOut Networks: $a_{i} = \mathbf{b}_{i} + \mathbf{W}_{i}\mathbf{h}$ and $h = \max_{i}a_{i}$
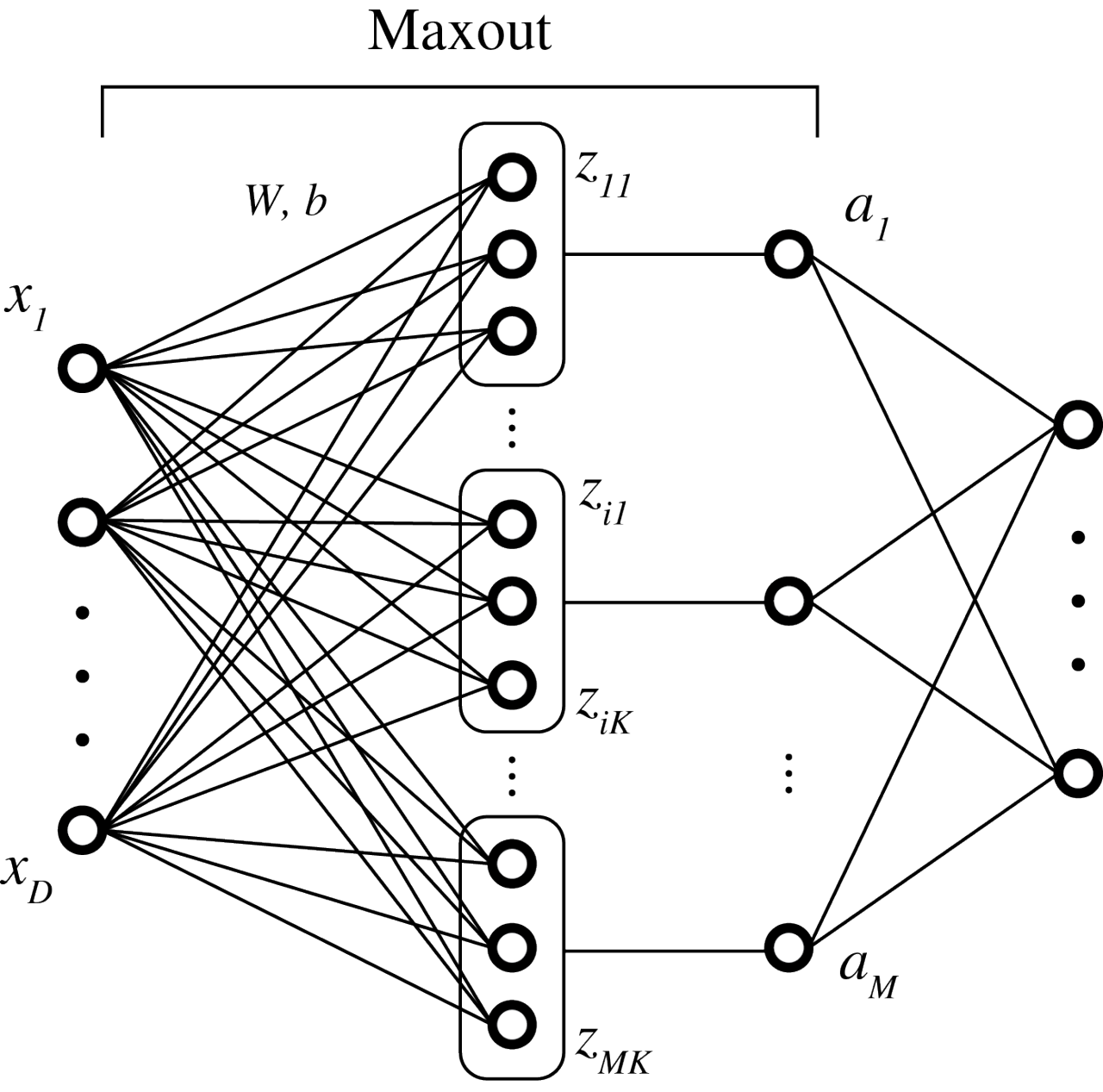
Dropout and Dropconnect


- Dropout
- randomly drop nodes for each sample at training
- keep all nodes at testing
- Dropconnect
- randomly drop connections for each sample at training
- keep all connections at testing
Data Augmentation
- Random Data Transformations
- translations, rotations, scaling (spatial or temporal)
- random segments of signals (partial observations)
- random color and contrast variations














More Data Augmentation
- PCA on channel space:
- Compute the PCA of signal values in each channel.
- Sample PCA coefficients and generate offsets for each channel.
- Add the offsets to every value in the channel.
- Improves image recognition performance by about 1%.
Data Augmentation
- Random mix/combinations of:
- translation
- rotation
- stretching
- shearing
- lens distortion
- really go crazy
Data Augmentation: Today

Auto Augmentation: Future Beckons



- Cubuk et.al. "AutoAugment: Learning Augmentation Policies from Data", CVPR 2019
Regularization: Key Idea
- Training: Add some randomness
- Testing: Marginalize over randomness
- Examples:
- Dropout
- Batch Normalization
- Data Augmentation
- DropConnect
- Fractional Max Pooling
- Stochastic Depth
- Cutout
- MixUp
Summary
- Consider using dropout for large fully connected layers
- Using batch normalization and data augmentation almost always as good idea
- Try cutout and mixup especially for small classification datasets
Choosing Hyperparameters: A Recipe
- Step 1: Check initial loss
- Step 2: Overfit a small sample
- Step 3: Find LR that makes loss go down
- Step 4: Coarse grid, train for 1-5 epochs
- Step 5: Refine grid, train longer
- Step 6: Look at learning curves
- Step 7: GOTO Step 5
- Step 1: Turn of weight decay, sanity check loss at initialization.
- Step 2: Try to get perfect accuracy on a small sample of data (5-10 minibatches)
- fiddle architecture, LR, weight initialization, turn off regularization
- Loss not going down? LR too low or bad initialization
- Loss explodes to Inf or NaN? LR too high or bad initialization
- Step 3: Use architecture from previous step, use all training data, turn on weight decay, find LR that makes loss drop significantly within first 100 iterations
- Good learning rates to try: 1e-1, 1e-2, 1e-3, 1e-4
- Step 4: Choose a few values of LR and weight decay around what worked from Step 3, train a few models for 1-5 epochs.
- Good weight decay to try: 1e-4, 1e-5, 0
- Step 5: Pick best models from Step 4, train them longer (10-20 epochs) without LR decay
Interpreting Learning Curves
- Losses may be noisy, use scatter plot and also plot moving average to see trends better.
Bad Initialization
Loss Plateaus
Early LR Drop
Accuracy Curves
After Training
Model Ensembles
- Train multiple independent models
- At test time average their results
- take average of predicted probability distributions, then choose argmax
- Enjoy 2% extra performance
How do we get multiple models?
- Same architecture, different initialization:
- Use cross-validation to determine best hyper-parameters.
- Train multiple models, each with different initialization.
- Create model ensemble from top cross-validation models
- Create model ensemble from different checkpoint of the same model
- Train each model on different subset of data
Stochastic Weight Averaging
- Instead of using actual parameter vector, use average weights over last few epochs.


Transfer Learning
Transfer
- "You need a lot of data if you want to train/use CNNs"
Problem Setup
| similar dataset | different dataset | |
|---|---|---|
| very little data (10s to 100s) | use linear classifier as top layer | difficult setup, try linear classifier from different stages |
| lots of data (100s to 1000s) | fine tune few layers of existing network | fine tune many layers or train from scratch |
- Common Practical Tricks
- Fine-tuning existing well trained models.
- Balancing imbalanced datasets.
- Multi-Task Learning (combining loss functions)
Transfer Learning with CNNs


Fine Tuning
- Train with feature extraction first before fine-tuning.
- i.e., train last classifier layer first before updating the other layers
- Use lower the learning rate.
- typically $\frac{1}{10}$ LR used in original training
- Sometimes freeze lower layers to save computation
Transfer Learning is Pervasive
- It is the norm, not the exception.
- Image Captioning
- Almost all NLP tasks
- Train large language models: BERT, GPT-3 etc.
- Fine-tune for downstream tasks
- Caveats
- Training from scratch works as well as pre-training on ImageNet
- If you train for 3x as long
- Summary
- Pretrain+finetuning trains faster, so practically useful
- Training from scratch works well if you have enough data
Summary
- Lots of small tricks: before, during, after training
- All add up to help effectively train neural networks
- Keep track of latest trends from papers to see what current best practices are.