Supervised Learning Applications
CSE 891: Deep Learning
Deep Learning Applications





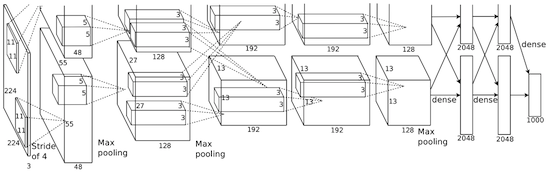
Classification: Object Recognition

Object Detection

Object Detection
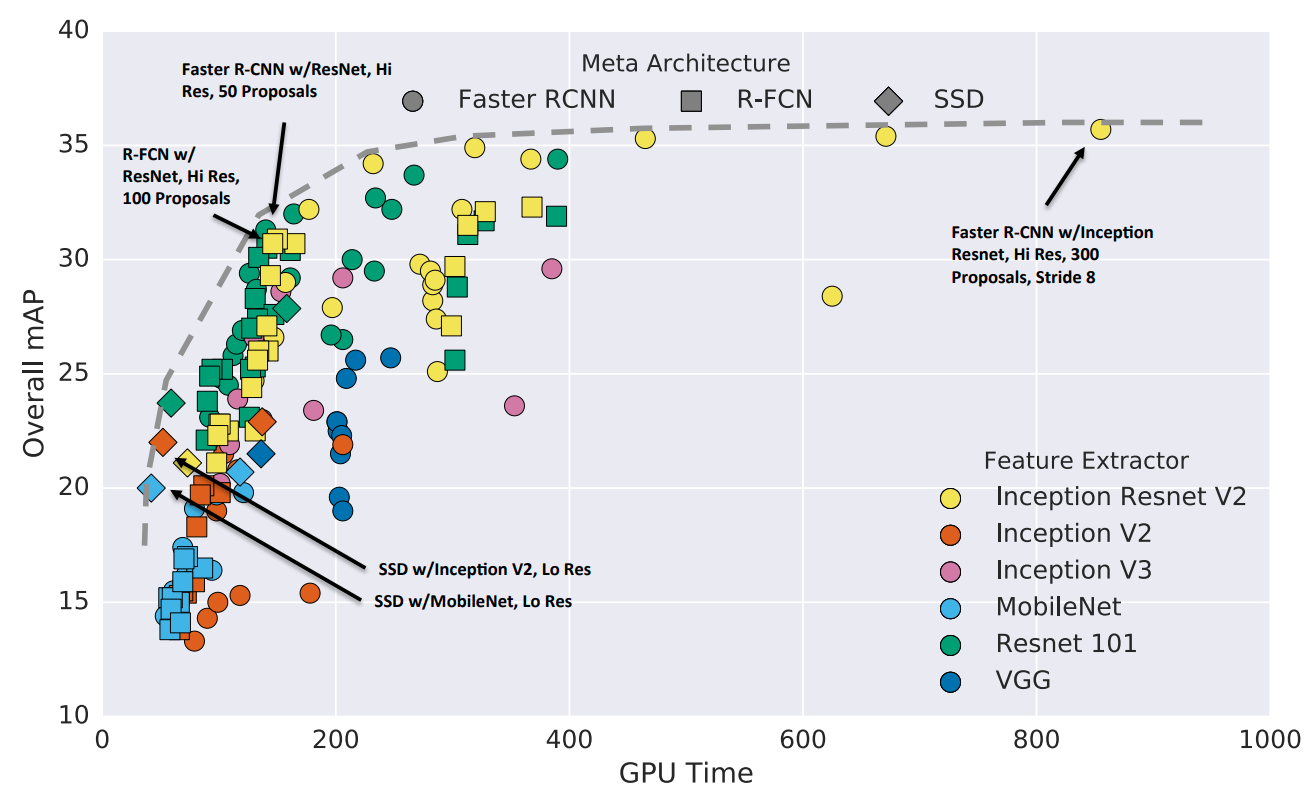
Object Detection
- Key ideas today:
- train longer
- multi-scale backbone: feature pyramid networks
- bigger backbones: e.g., ResNeXt
- very big models work better
- big ensembles, more data, etc
- test-time augmentations
Detection with CornerNet
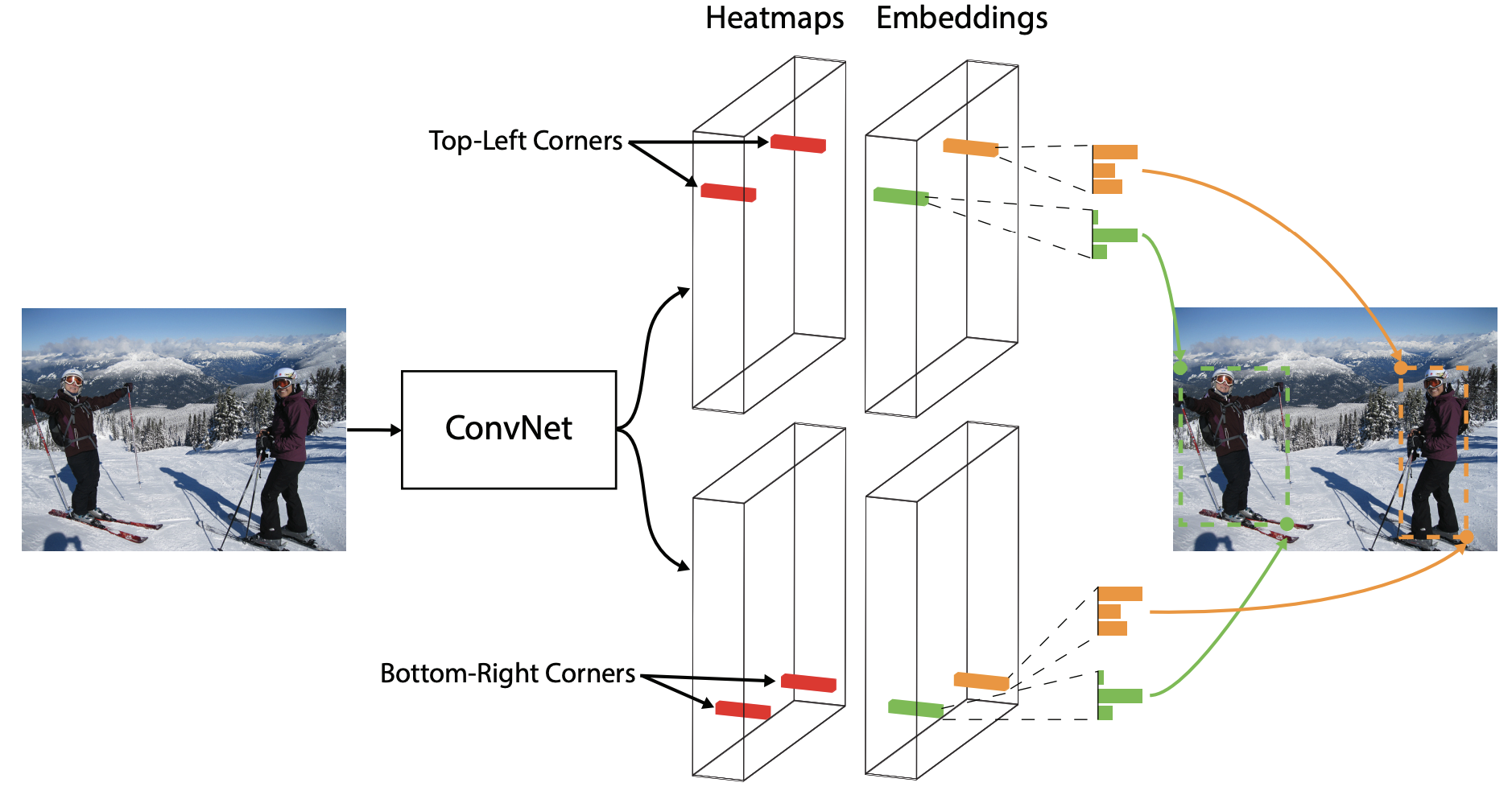
- Law and Deng, "CornerNet: Detecting Objects as Paired Keypoints", ECCV 2018
Face Matching
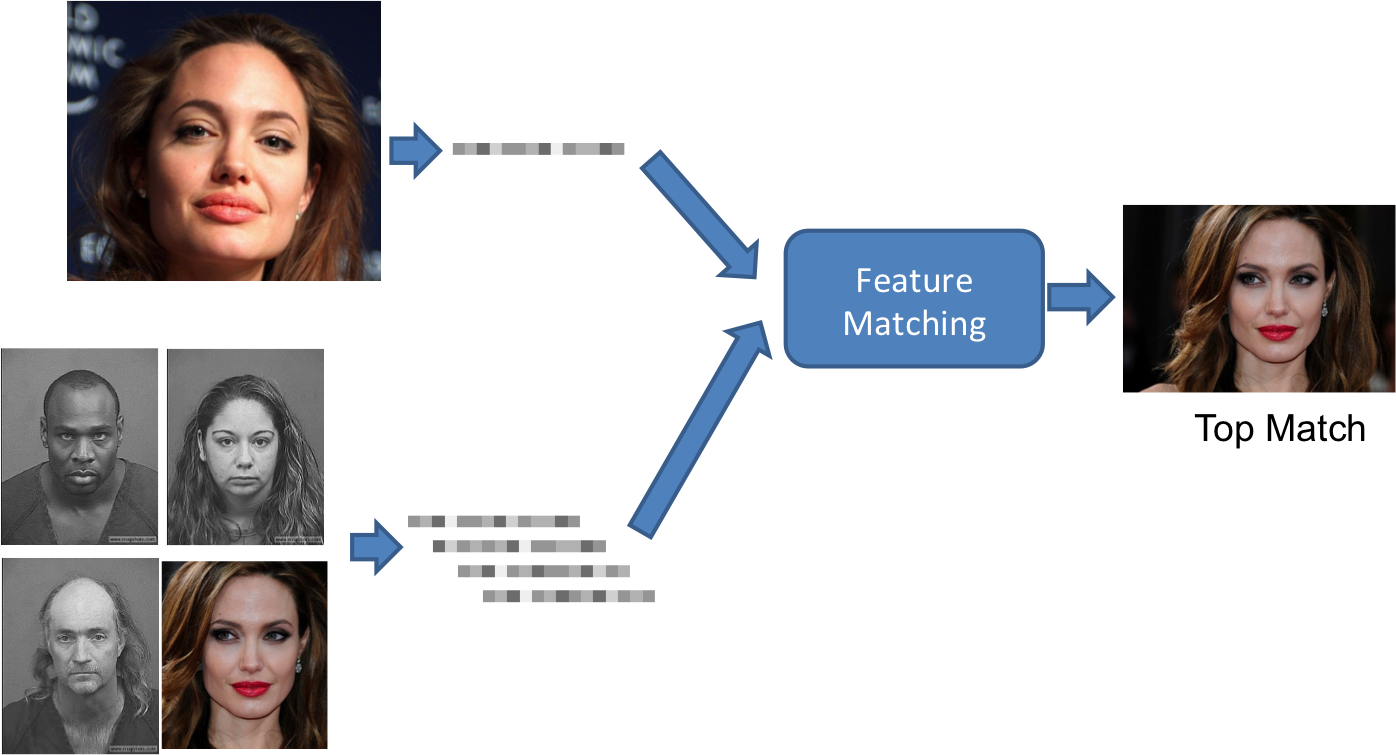
Feature Extraction

Face Recognition Models

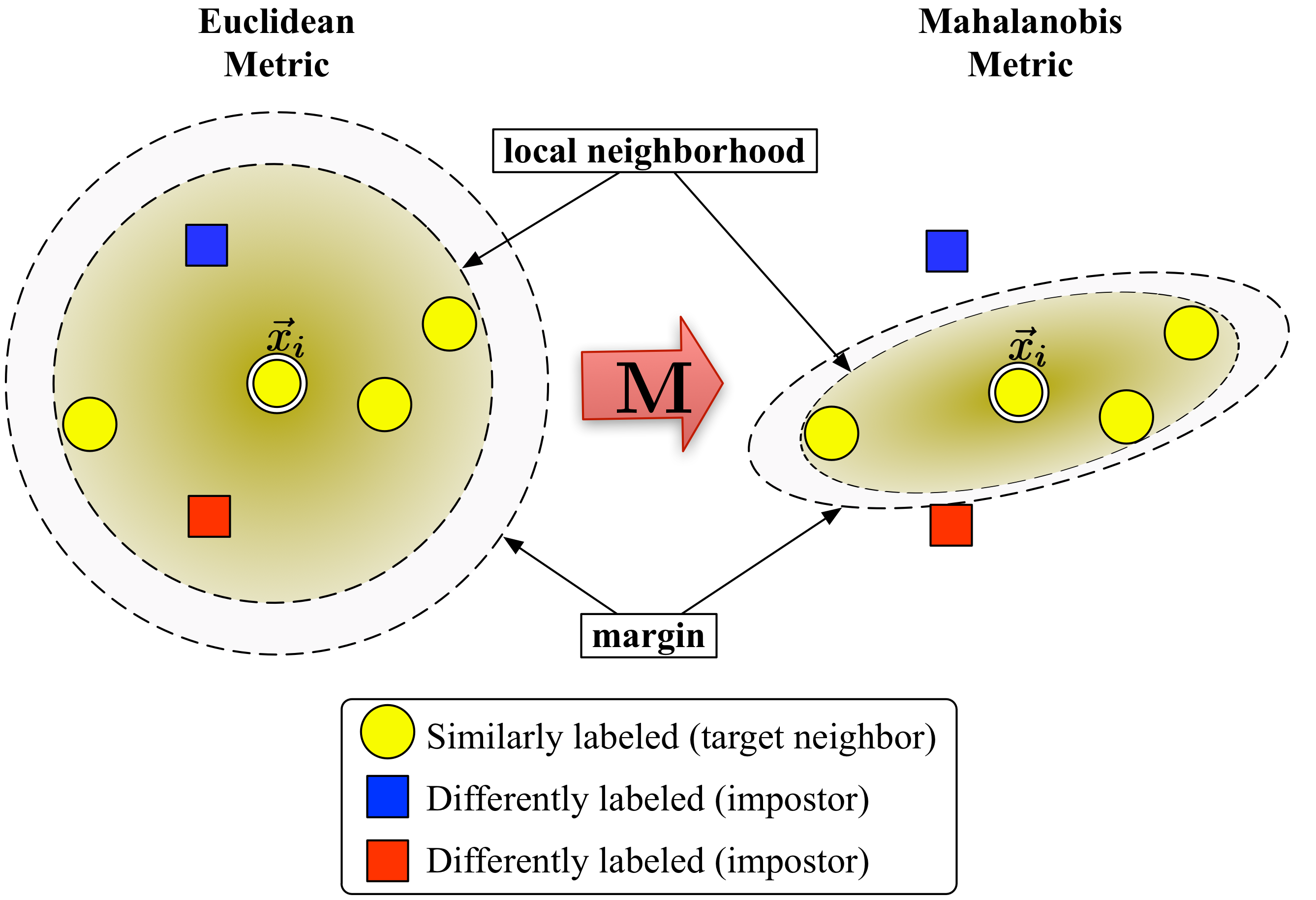
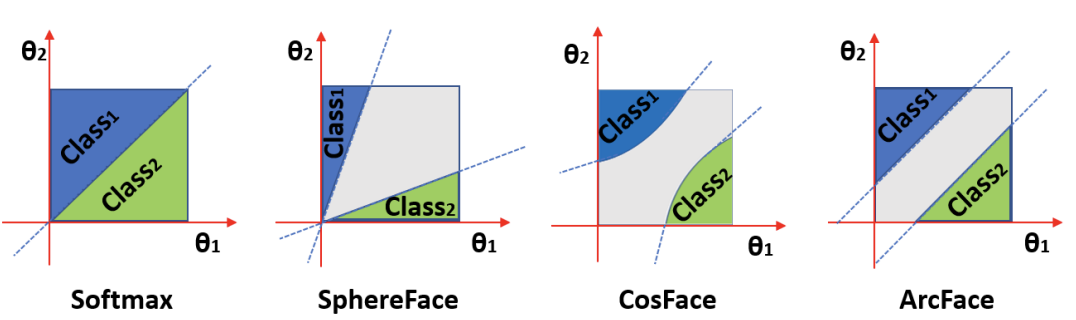
Loss Functions: Embeddings
- Cosine Distance: $\frac{\mathbf{x}^T\mathbf{y}}{\|x\|\|y\|}$
- Triplet Loss: $\left(1+d(\mathbf{x}_i,\mathbf{x}_j)-d(\mathbf{x}_i,\mathbf{x}_k)\right)_{+}$
- Mahalanobis Distance: $(\mathbf{x}-\mathbf{y})^T\mathbf{M}(\mathbf{x}-\mathbf{y})$
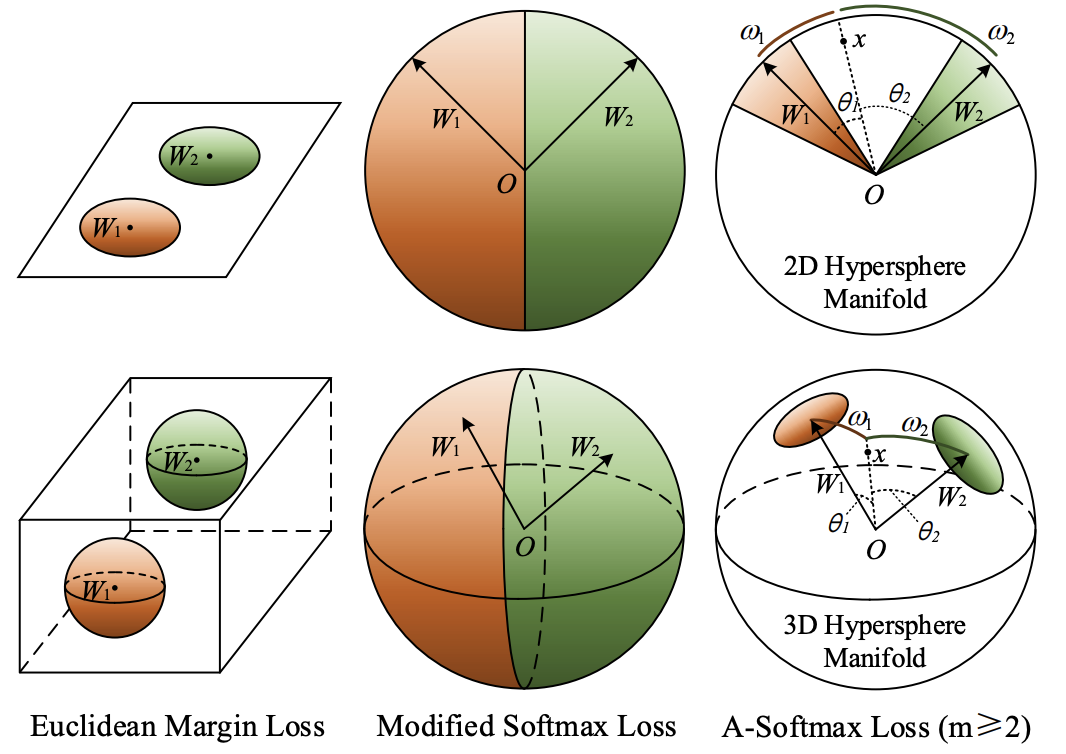
Angular Loss Functions
- Angular Margin Losses:
- Angular Softmax (SphereFace CVPR'17) $$\frac{1}{N}\sum_{i=1}^N\log\left(\frac{e^{\|\mathbf{x}_i\|cos(m\theta_{y_i,i})}}{e^{\|\mathbf{x}_i\|cos(m\theta_{y_i,i})}+\sum_{j\neq y_i}e^{\|\mathbf{x}_i\|cos(m\theta_{j,i})}}\right)$$
- Additive Angular Softmax (ArcFace CVPR'19) $$-\frac{1}{N}\sum_{i=1}^N\log\left(\frac{e^{scos(\theta_{y_i}+m)}}{e^{scos(\theta_{y_i}+m)}+\sum_{j\neq y_i}e^{scos(\theta_j)}}\right)$$

Regression: Semantic Segmentation
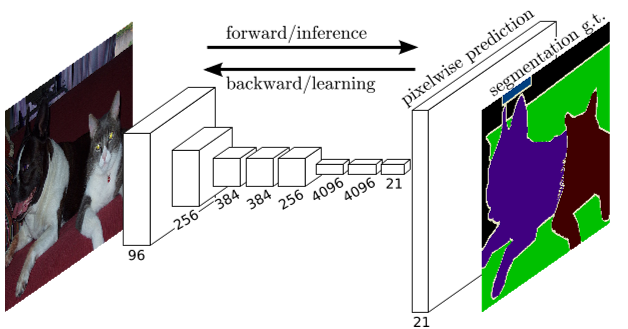
Regression: Semantic Segmentation

Regression: Instance Segmentation

Regression: Super-Resolution


Bayesian Deep Learning
- Model Output Uncertainty: $p(\mathbf{y}^{*}|\mathbf{x}^{*}, \mathbf{X},\mathbf{Y})$
- Model Parameter Uncertainty: $p(\mathbf{w}^{*}|\mathbf{x}^{*},\mathbf{X},\mathbf{Y})$
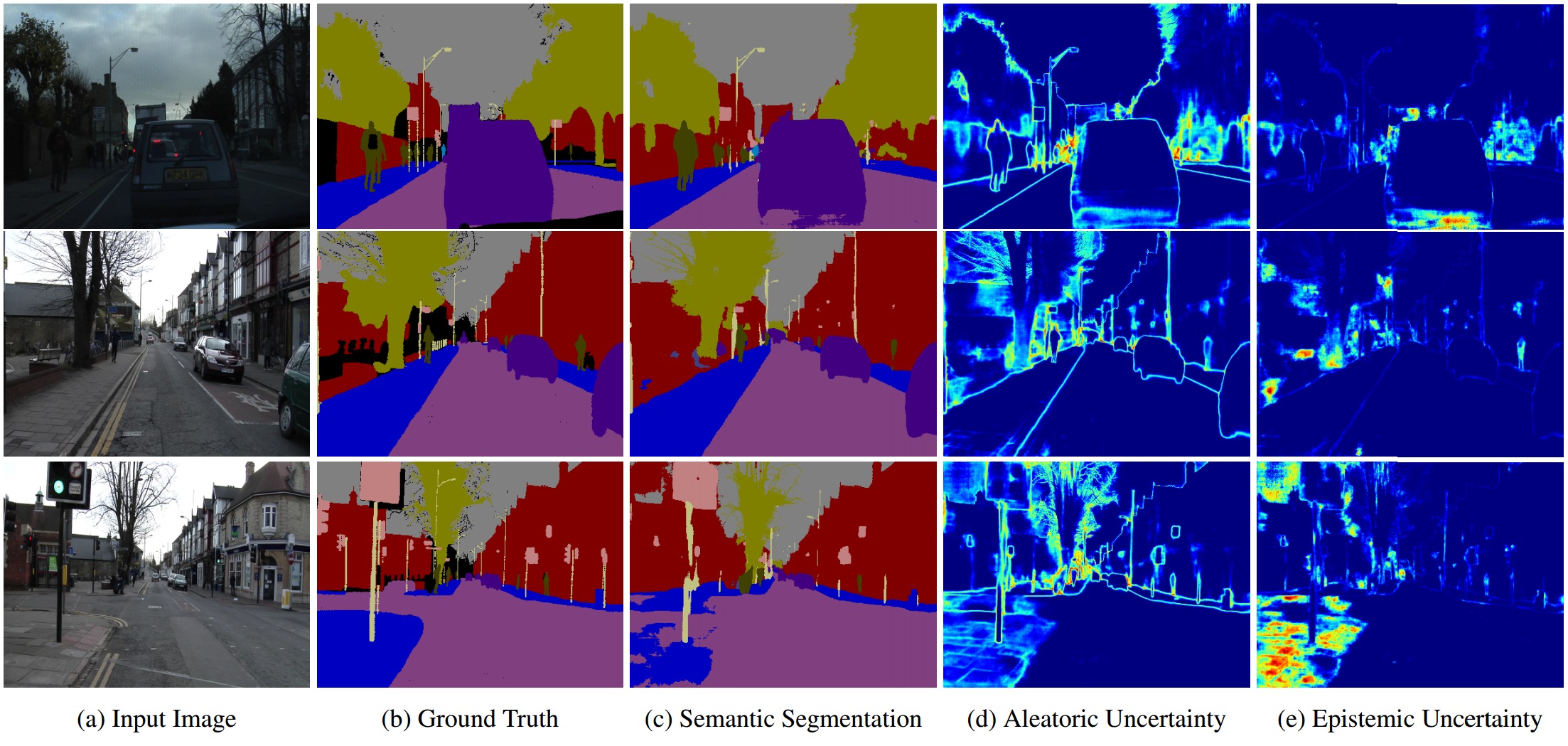 \begin{eqnarray}
p(\mathbf{y}^{*}|\mathbf{x}^{*}, \mathbf{X},\mathbf{Y}) = \int p(\mathbf{y}^{*}|\mathbf{w}^{*})p(\mathbf{w}^{*}|\mathbf{x}^{*},\mathbf{X},\mathbf{Y})d\mathbf{w}^{*} \nonumber
\end{eqnarray}
\begin{eqnarray}
p(\mathbf{y}^{*}|\mathbf{x}^{*}, \mathbf{X},\mathbf{Y}) = \int p(\mathbf{y}^{*}|\mathbf{w}^{*})p(\mathbf{w}^{*}|\mathbf{x}^{*},\mathbf{X},\mathbf{Y})d\mathbf{w}^{*} \nonumber
\end{eqnarray}
3D Computer Vision
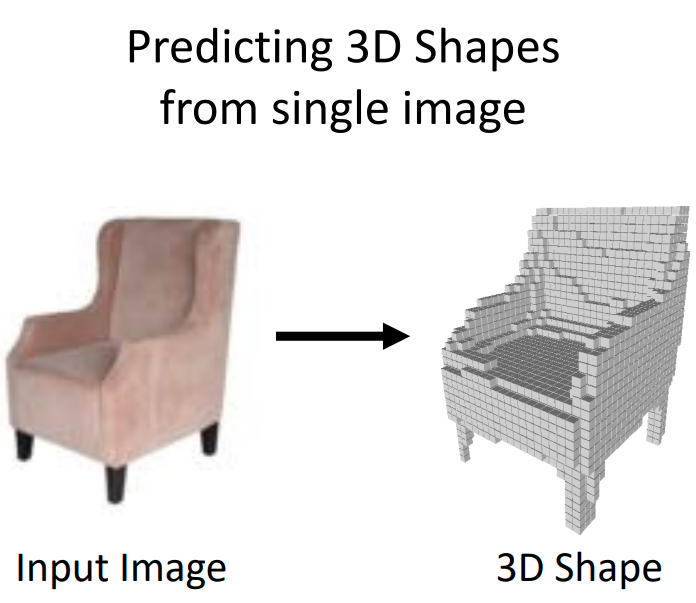

3D Representations
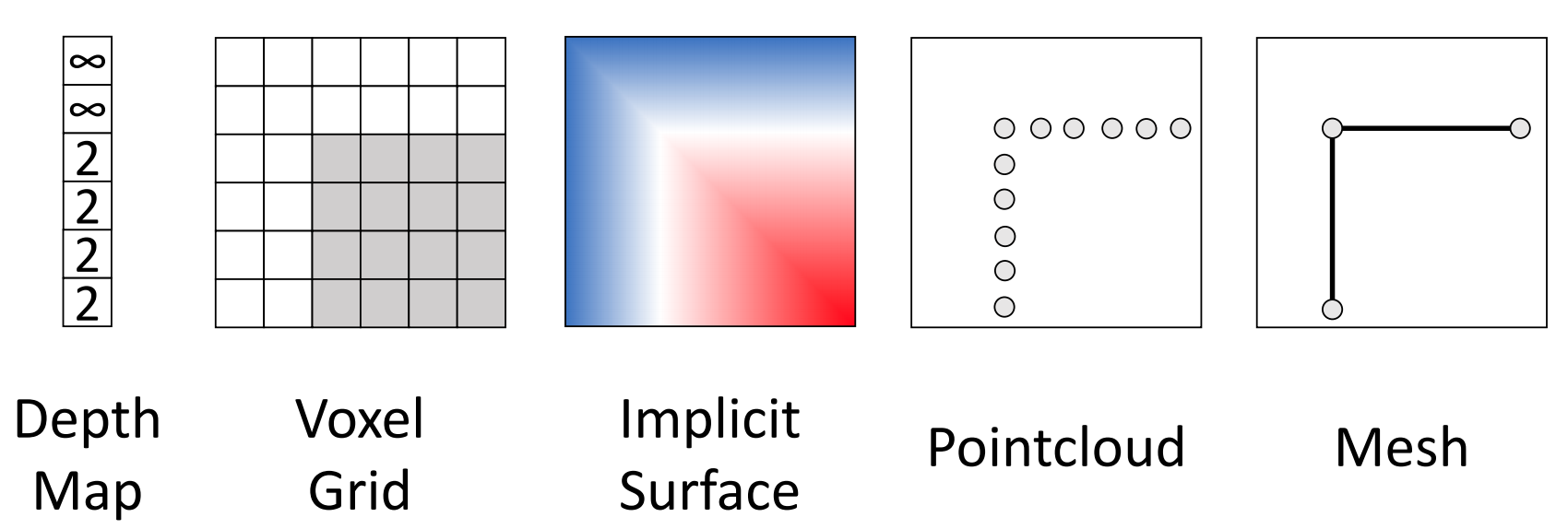
Depth Estimation

Depth Estimation Network
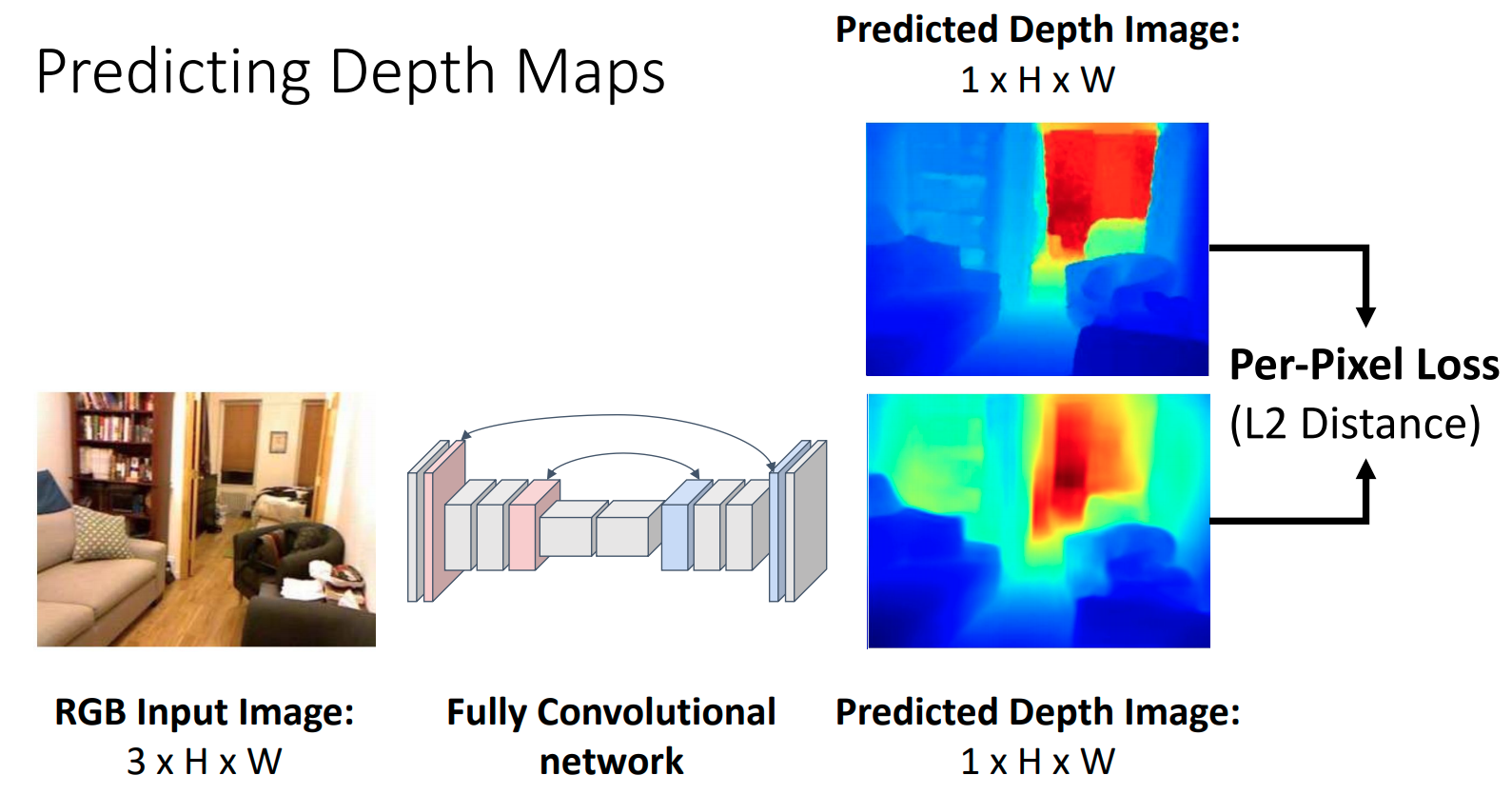
- Eigen, Puhrsh, and Fergus, “Depth Map Prediction from a Single Image using a Multi-Scale Deep Network”, NeurIPS 2014
- Eigen and Fergus, “Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture”, ICCV 2015
- Slide Credit: Justin Johnson
Depth Estimation Loss
- $L_2$ distance is scale variant
- Absolute scale/depth are ambiguous from a single image
- We need a scale invariant loss $$ \begin{equation} D(\mathbf{y},\mathbf{y}^*) = \frac{1}{2n^2}\sum_{i,j} \left( (\log y_i - \log y_j) - (\log y^*_i - \log y^*_j) \right)^2 \end{equation} $$
3D Surface Normal Estimation

3D Surface Normal Estimation Network

- Eigen and Fergus, “Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture”, ICCV 2015
- Slide Credit: Justin Johnson
Pixel2Mesh
- Key Ideas:
- Iterative Refinement
- Graph Convolution
- Vertex ALigned Features
- Chamfer Loss Function
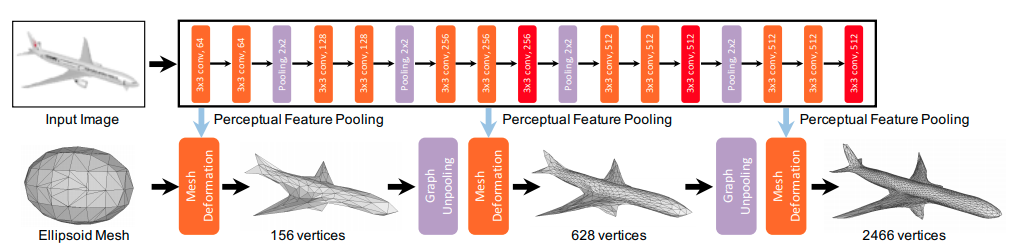
- Wang et al, "Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images", ECCV 2018
Neural Radiance Fields

- Mildenhall et al, ”NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”, ECCV 2020
3D Face Reconstruction from a Single Image
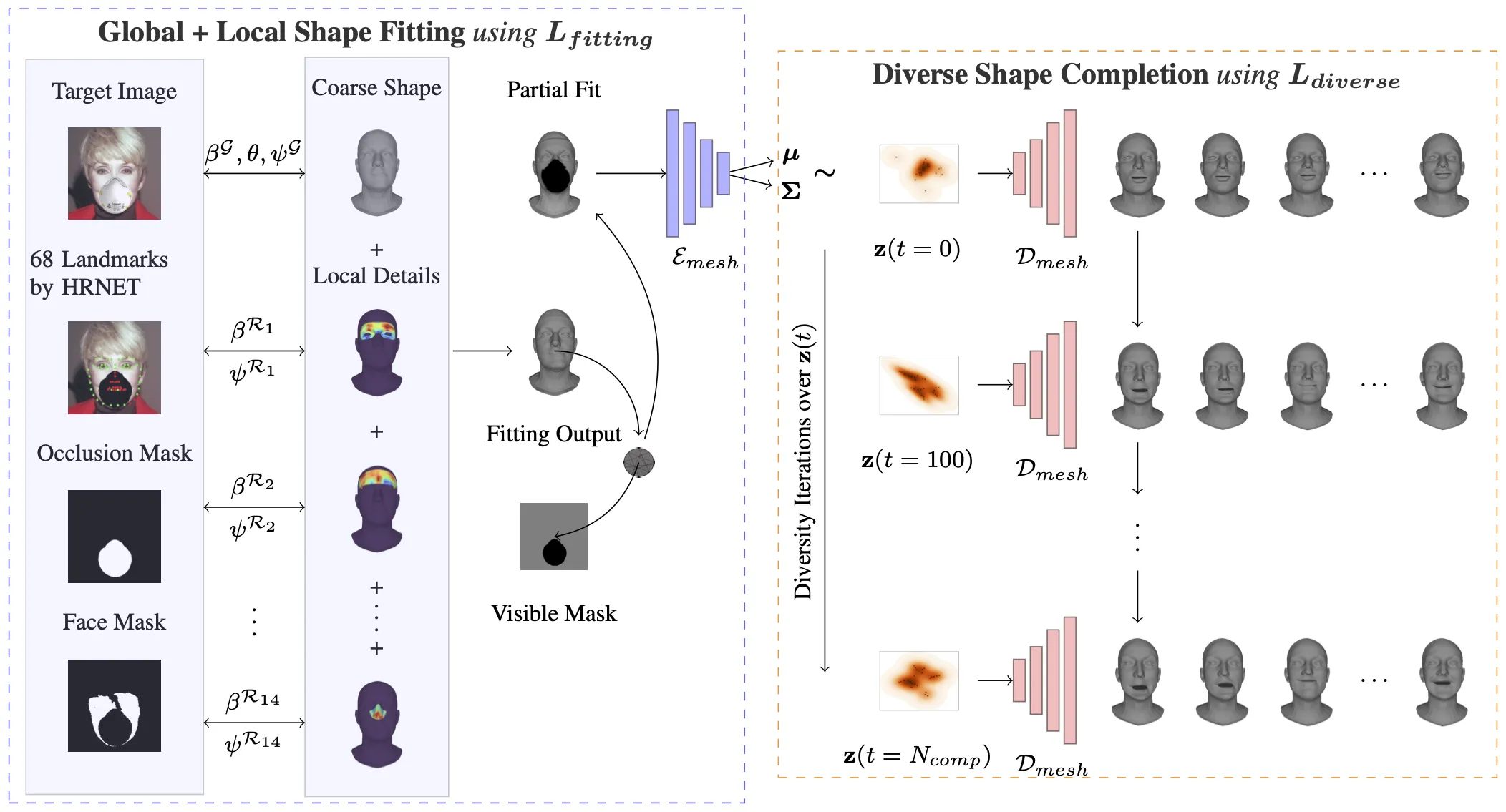
- Rahul Dey and Vishnu Boddeti, ”Generating Diverse 3D Reconstructions from a Single Occluded Face Image,” CVPR 2022
Face Inpainting
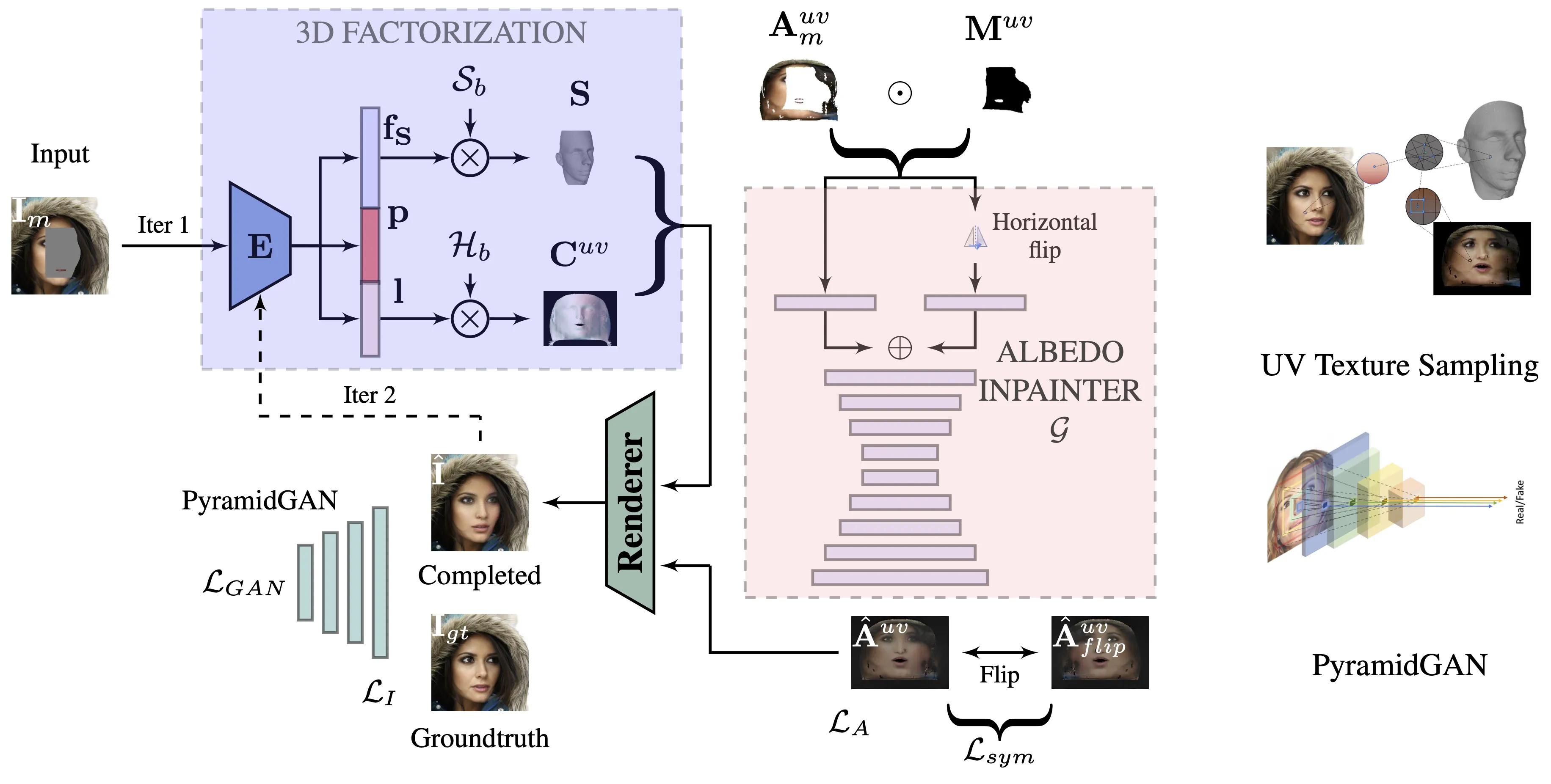
- Rahul Dey and Vishnu Boddeti, ”3DFaceFill: An Analysis-By-Synthesis Approach to Face Completion,” WACV 2022
Motion Deblurring
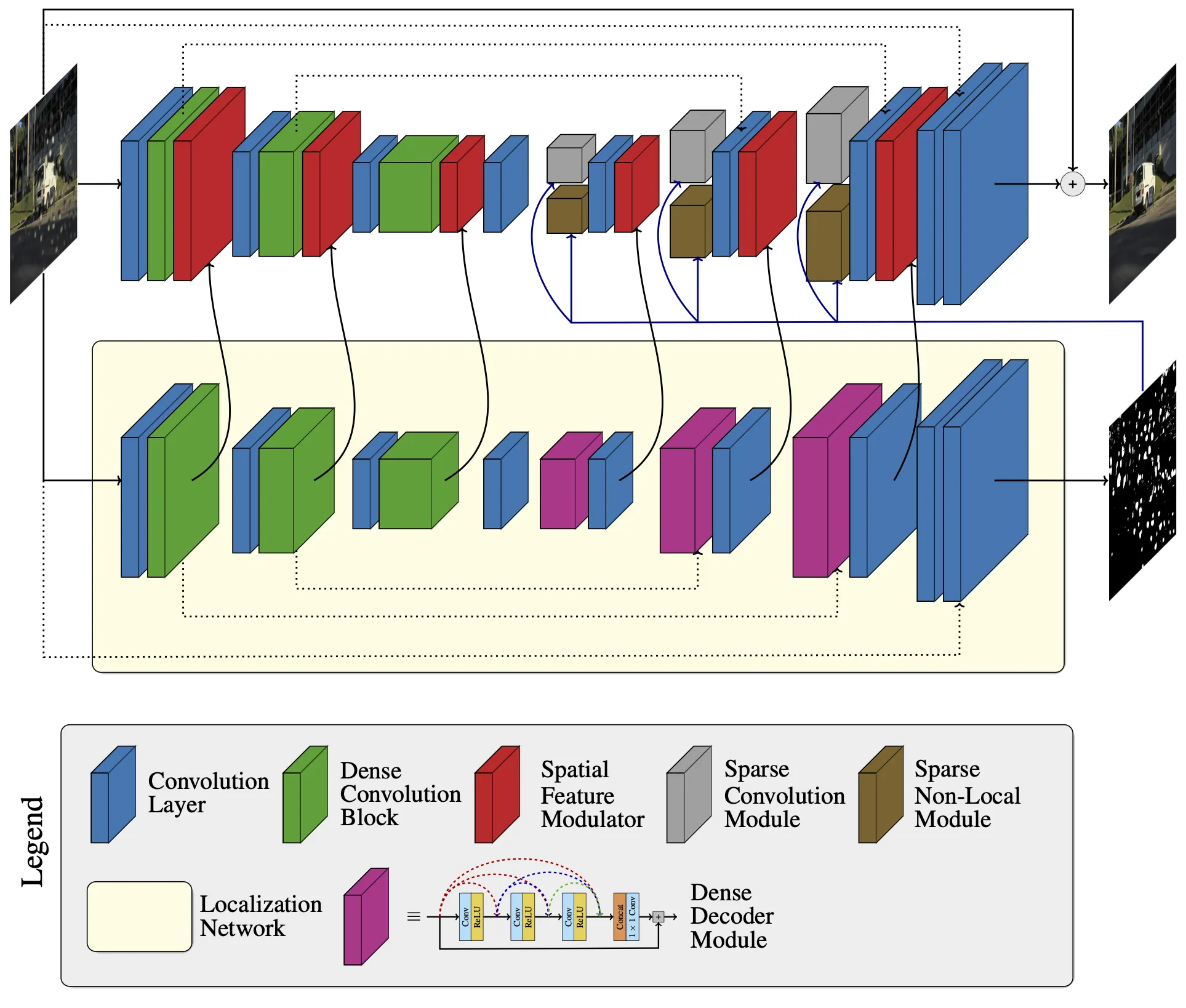
- Purohit et al "Region-Adaptive Dense Network for Efficient Motion Deblurring" AAAI 2019
- Purohit et al "Spatially-Attentive Patch-Hierarchical Network for Adaptive Motion Deblurring" CVPR 2020
- Purohit et al "Spatially-Adaptive Image Restoration using Distortion-Guided Networks" ICCV 2021
Motion Deblurring Results


Video from Single Motion Blurred Image


- Purohit et al "Bringing Alive Blurred Moments" CVPR 2019
Video from Single Motion Blurred Image
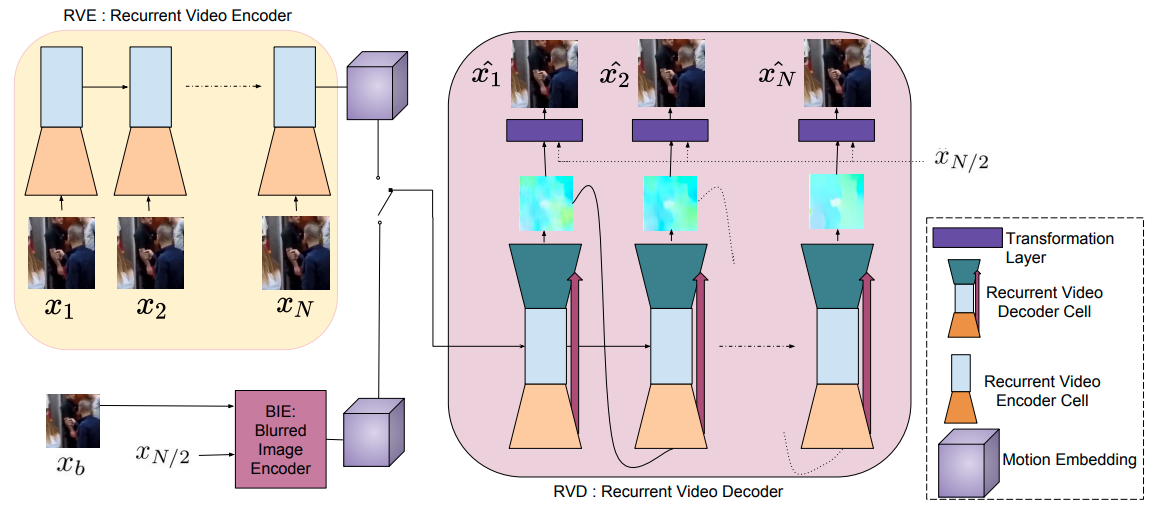
- Purohit et al "Bringing Alive Blurred Moments" CVPR 2019