Primarily driven by skilled practitioners and elaborated design.
a.k.a "Graduate Student Design"
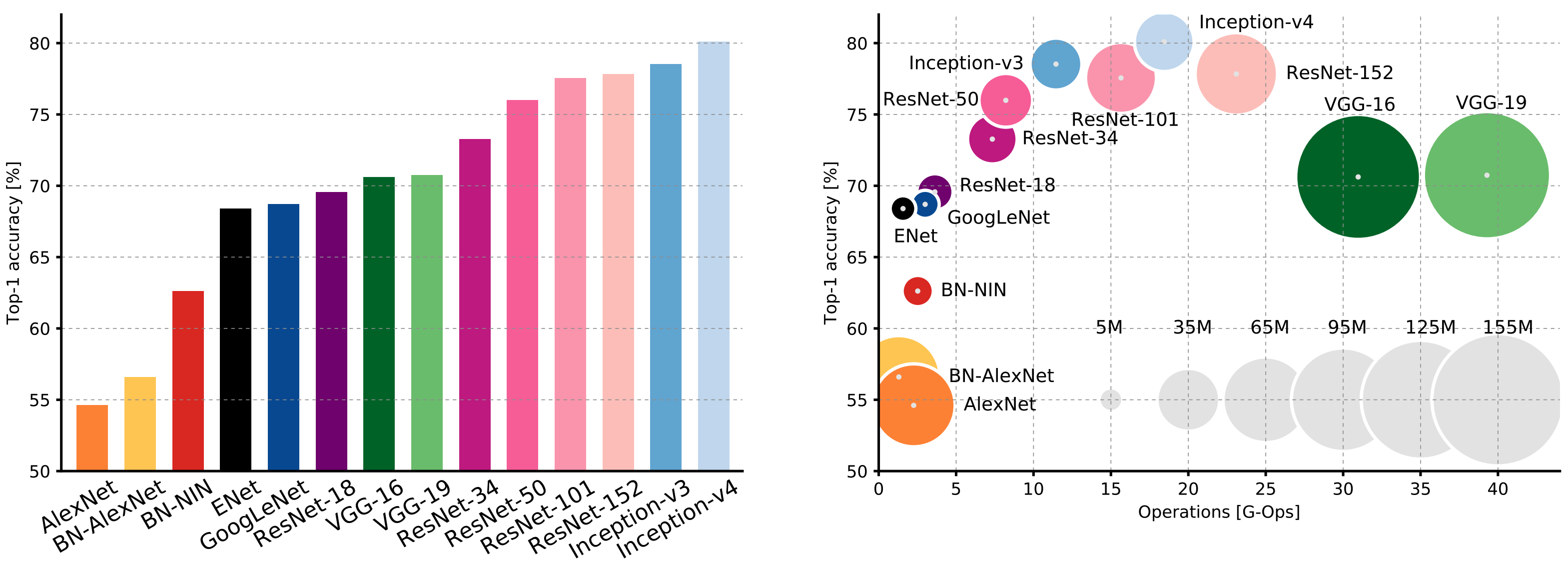
AlexNet
5 convolutional layers, 3 fully connected layers
60 million parameters
GPU based training
established that deep learning works for computer vision !!
Krizhevsky et.al. "ImageNet Classification with Deep Convolutional Neural Networks" NeurIPS 2012
VGG: Deeper Networks
19 layers deep, 3 fully connected layers
144 million parameters
$3 \times 3$ convolutional filters with stride 1
$2 \times 2$ max-pooling layers with stride 2
Established that smaller filters (are parameter efficient) and deeper networks are better !!
Two $3\times 3$ conv layer has same receptive field but has fewer parameters and takes less computation.
Simonyan et.al. "Very Deep Convolutional Networks for Large-Scale Image Recognition" ICLR 2015
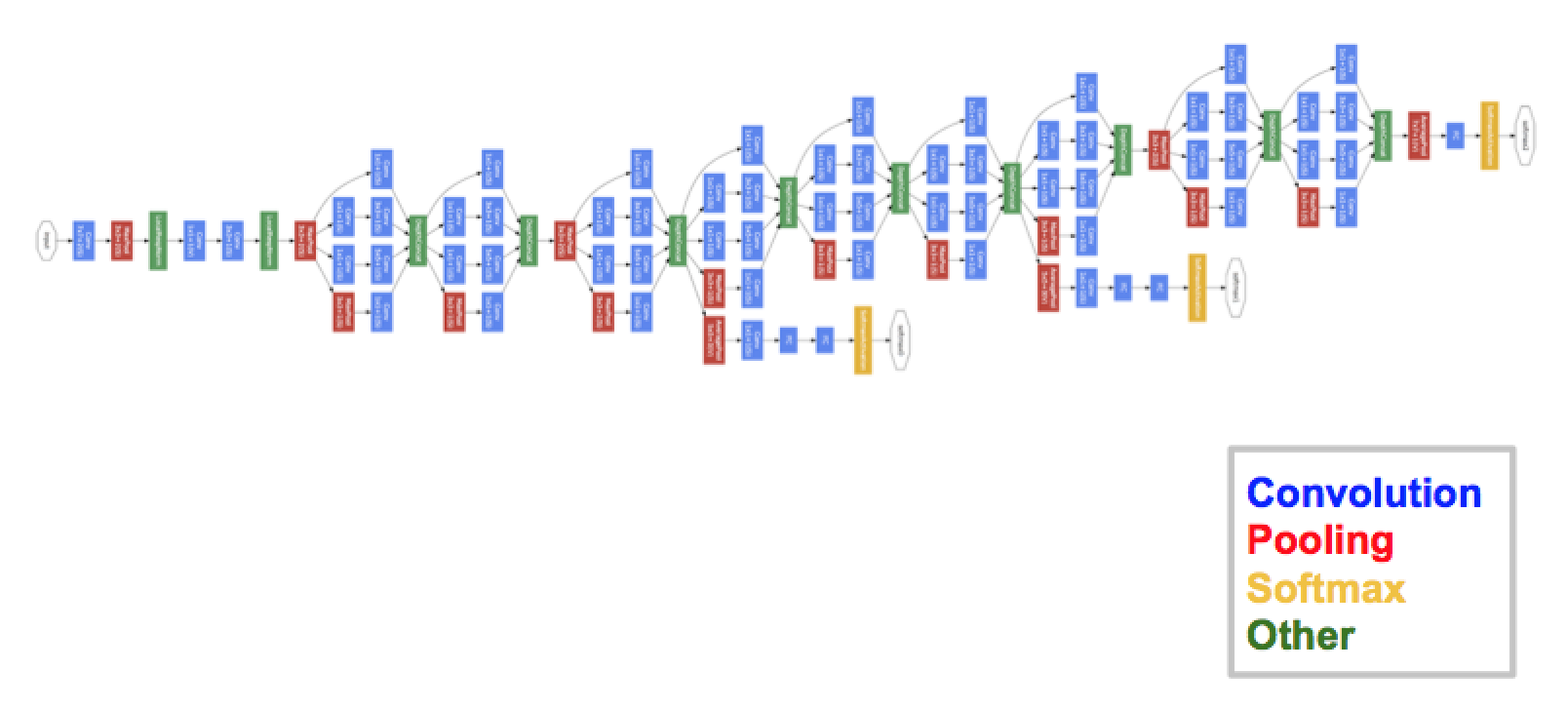
GoogLeNet: Focus on Efficiency
22 layers, introduced the "inception" module
efficient architecture - in terms of computation
compact model (about 5 million parameters)
computational budget - 1.5 billion multiply-adds
Szegedy et.al. "Going deeper with convolutions" CVPR 2015
GoogLeNet: Inception Module
Inception module: local unit with parallel branches
Local structure repeated many times throughout the network
Use $1\times 1$ "Bottleneck" layers to reduce channel dimension before expensive conv (we will revisit this with ResNet!)
Szegedy et.al. "Going deeper with convolutions" CVPR 2015
GoogLeNet: Auxiliary Classifiers
Training using loss at the end of the network didn't work well: Network is too deep, gradients don't propagate cleanly
As a hack, attach "auxiliary classifiers" at several intermediate points in the network that also try to classify the image and receive loss
GoogLeNet was before batch normalization! With BatchNorm no longer need to use this trick
Deeper Networks
Stack More Layers?
Once we have Batch Normalization, we can train networks with 10+ layers. What happens as we go deeper?
Deeper model does worse than shallow model!
Initial guess: Deep model is overfitting since it is much bigger than the other model
In fact the deep model seems to be underfitting since it also performs worse than the shallow model on the training set! It is actually underfitting
Training Deeper Networks
A deeper model can emulate a shallower model: copy layers from shallower model, set extra layers to identity
Thus deeper models should do at least as good as shallow models
Hypothesis: This is an optimization problem. Deeper models are harder to optimize, and in particular don’t learn identity functions to emulate shallow models
Solution: Change the network so learning identity functions with extra layers is easy!
Residual Units
Solution: Change the network so learning identity functions with extra layers is easy!

























 $$
\begin{eqnarray}
\mbox{Speedup } \approx 9
\end{eqnarray}
$$
$$
\begin{eqnarray}
\mbox{Speedup } \approx 9
\end{eqnarray}
$$





